
Iceberg は ACID トランザクションをサポートしており、複雑で並行性のあるデータ操作においてもデータの完全性と信頼性を確保します。

Apache Iceberg とは?
Apache Iceberg は、データレイク内の大規模データセットを管理するために設計されたオープンソースのテーブルフォーマットです。従来の Apache Hive などのテーブルフォーマットが抱える制約、特に大容量データの効率的かつ一貫性のある処理に対応するために開発されました。

信頼性の高いデータ整合性
非破壊的なスキーマ進化
Iceberg はスキーマ進化(Schema Evolution)に対応しており、スキーマの変更(カラムの追加・削除・リネームなど)を段階的に適用できます。これにより、稼働中の処理に影響を与えることなくスキーマを柔軟に更新できます。
クエリ性能の向上
データプルーニングやパーティション認識などの機能により、Iceberg はクエリ時にスキャンするデータ量を大幅に削減し、大規模データセットにおいても高速なクエリを実現します。
Iceberg ユースケース - ゲーム業界
現代のゲームは膨大なデータを生成します。ストレージはコストを抑えるだけでなく、データサイロを解消し、チームやスタジオをまたいで誰もがデータを最大限に活用できるようにする上で重要な役割を果たします。
Tencent Gaming がすべてのワークロードを Apache Iceberg に統合することで、事前集計をすべて排除しつつ、ストレージコストを15倍削減した方法をご覧ください。ケーススタディを読む。

Apache Iceberg の代替案
Iceberg が合わない場合は、他の人気のあるオープンレイクハウステーブルフォーマットの選択肢もご確認ください。

Apache Hudi
リアルタイムデータの取り込みやアップサート機能で知られる Hudi は、低レイテンシなデータ更新や高速なデータ取り込みが求められるシナリオにおいて優れた性能を発揮し、増分処理にも対応しています。
Apache Paimon
Paimon はリアルタイムストリーミングデータおよび動的な Schema Evolution を強力にサポートしており、継続的なデータ更新やスキーマ変更が頻繁に発生する環境に適しています。

Delta Lake
Delta Lake は、強力な ACID トランザクション対応と Apache Spark エコシステムとのシームレスな統合により広く認知されており、大規模データ処理に Spark を活用しているユーザーにとっては非常に有力な選択肢です。
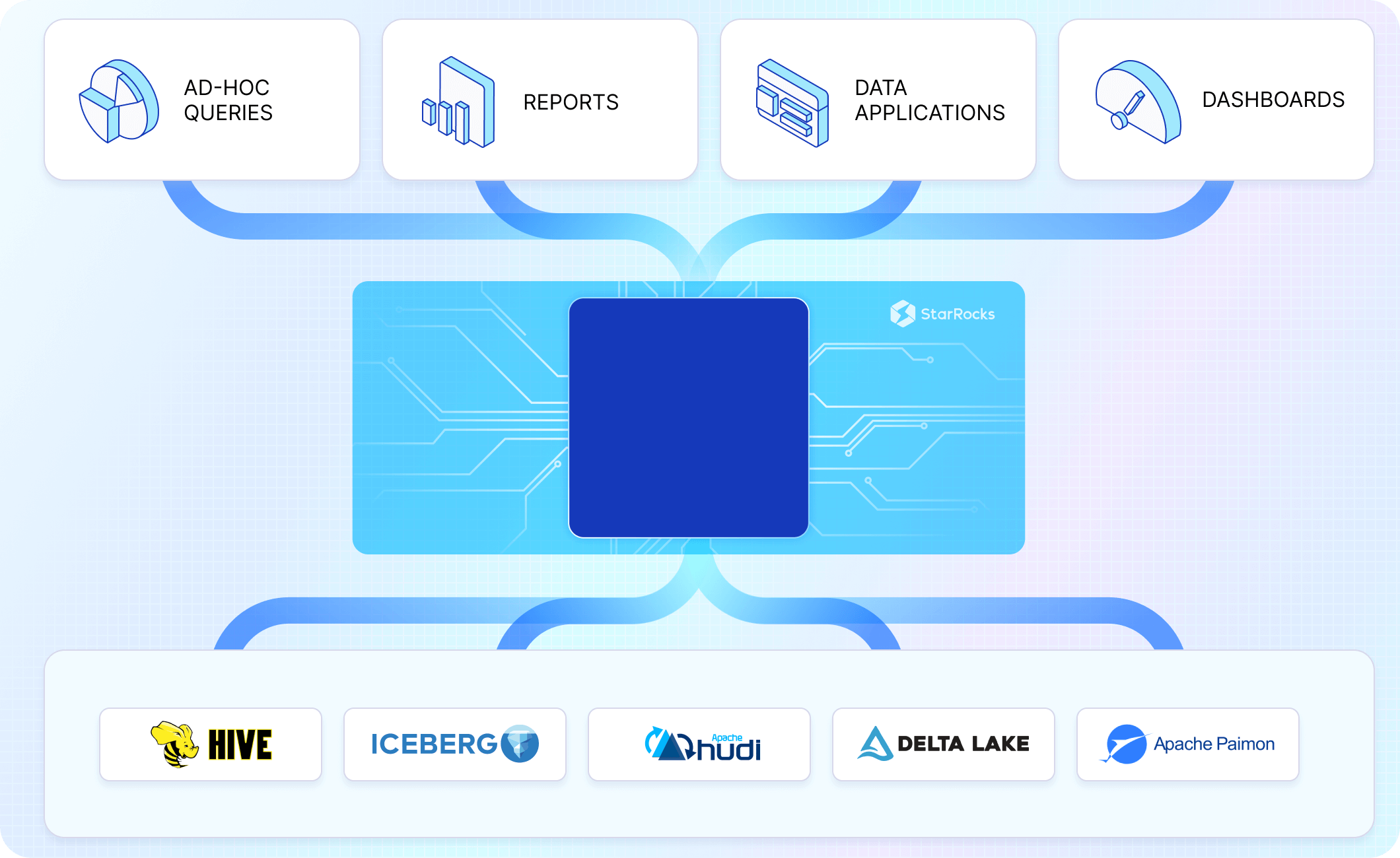
クエリエンジンのアップグレード
Apache Iceberg の潜在能力を最大限に引き出すには、CelerData のような高性能なクエリエンジンとの組み合わせが重要です。CelerData はデータウェアハウス型のワークロードに最適化されており、低レイテンシのクエリ処理や数万件規模の同時接続に対応します。また、Apache Iceberg 専用に設計された機能も備えており、データレイクハウスアーキテクチャの性能を最大限に活用できます。
ユースケース:データレイク向けクエリエンジン
Iceberg の導入は、優れたレイクハウス構築の第一歩です。成功には、適切なクエリエンジンの選定も欠かせません。以下に代表的なユースケースを紹介します。
ソーシャルメディア
ある大手ソーシャルメディア企業は、データレイクハウスアーキテクチャへ移行することで、1日あたり数兆件にのぼるデータの処理において、開発サイクルの短縮とコスト効率の向上を実現しました。

トラベル
Trip.com は従来のデータウェアハウスを廃止し、データレイクハウス用クエリエンジンに切り替えることで、クエリ性能を10倍向上させました。

Eコマース
ある環境系製造企業は、最新のオープンソースデータレイクハウスクエリエンジンへ移行することで、分析システムのコスト効率を10倍に高めました。
ソフトウェア
Tencent の A/B テスト向けSaaSプラットフォーム「ABetterChoice」は、要求の厳しいカスタマー向けワークロード をデータレイクハウス上に 統合しています。