課題
JDL(京東物流)は、5G、人工知能(AI)、ビッグデータ、クラウドコンピューティング、IoT(モノのインターネット)といった先端技術を活用し、業務全体を支える高度なプラットフォームを構築しました。このプラットフォームの上に、自動化されたサービス、業務のデジタル化、そしてインテリジェントな意思決定を実現するスマート物流システムを展開しています。
以下の図は、StarRocks導入前のJDLのアナリティクスプラットフォーム構成を示しています:
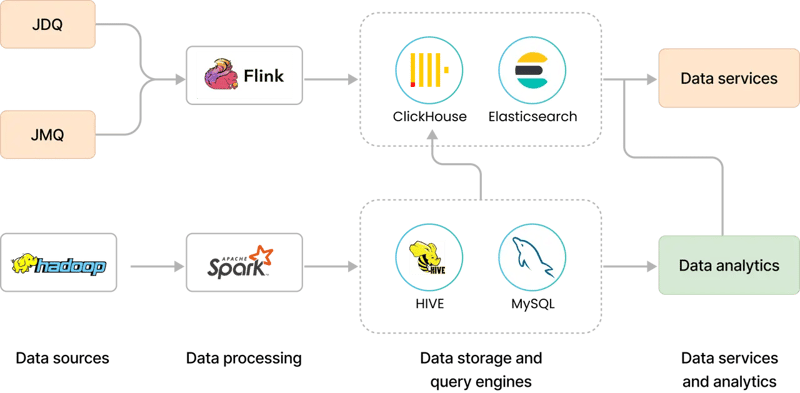
このプラットフォームには、大きく分けて2つのパイプラインが存在していました:
-
リアルタイムデータの処理:JDQ(Kafkaの実装)やJMQからデータを取り込み、Flinkで処理。
処理済みデータはClickHouseやElasticsearchに保存され、OLAPクエリ機能を通じてデータサービスおよびアナリティクスレイヤーに提供されていました。
-
バッチデータの処理:データレイク(HDFS)に保存されたデータをSparkで処理。Sparkの処理結果はHiveまたはMySQLに格納され、アナリティクスレイヤーからクエリが実行されていました。
しかし、企業全体でデジタルトランスフォーメーションへの投資が進む中、JDLの各事業部門ではリアルタイムなデータ分析の必要性が高まっていきました。とはいえ、これは言うほど簡単なことではありませんでした。既存のアナリティクスプラットフォームには、データのサイロ化、クエリ性能の低下、運用の複雑さ、開発サイクルの長期化といった深刻な課題が存在していたのです。
分断されたデータサービス
JDLでは、これまで新しいプロジェクトが立ち上がるたびに独自のデータサービスレイヤーが個別に構築されてきました。再利用を前提としない形で開発されていたため、同じような処理が何度も繰り返され、スケールメリットを活かすことが困難でした。
リアルタイムなデータ更新
JDLのビジネスはリアルタイムでの意思決定が不可欠であり、分析プラットフォームも、注文のキャンセルや更新などをリアルタイムに近い形で処理できる能力が求められていました。
しかし、従来のオフライン処理システムでは、こうした現代のビジネス要件には対応できません。
維持管理の悪夢
これらのデータサービスの運用・保守も非常に困難でした。特にホリデーシーズン中はその負担が顕著に表れます。統合された監視・トラフィック制御・障害対応の仕組みがないまま、数百ものデータサービスを管理しなければならず、DevOpsチームに大きな負荷がかかっていました。
高まるビジネス要求
データエンジニアは常に各事業部門からのデータ準備依頼に追われており、多くの作業は単調かつ繰り返しの多い業務となっていました。
データの所在が不明確
エンドユーザーにとって、必要なデータセットを見つけること自体が非常に困難でした。仮に要件に合いそうなデータを見つけられたとしても、明確かつ一貫性のあるメタデータ定義が存在しないため、実際には利用できないケースも多くありました。
データの利活用が困難
データが複数のシステムに分散して保存されており、分析や活用が難しい状態にありました。そのため多くのアナリストは、必要なデータをExcelにダウンロードして手作業で分析せざるを得ず、作業効率の低下やセキュリティリスクを招いていました。
クエリ速度の低下
クエリによっては完了までに数十秒〜数分かかることもあり、ユーザーの作業効率が落ち、業務フローを妨げる原因となっていました。結果として、ユーザーの不満や生産性の低下にもつながっていました。
複数のクエリエンジン
各システムが独自のSQL構文を持つクエリエンジンを使用しており、複数のデータソースを横断してクエリを実行するフェデレーション型システムの構築が非常に困難でした。
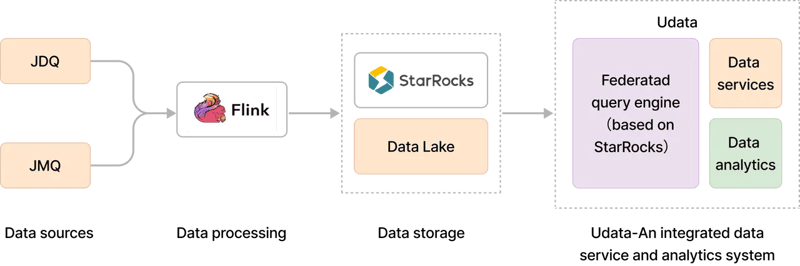
ClickHouseからの脱却 ― StarRocks世代のOLAPレイヤーによる統合メトリクスサービスの構築
このような課題に対応するため、JDLは「UData」と呼ばれる新たなメトリクスサービスプラットフォームを開発しました。
UDataはメトリクス生成プロセスを抽象化し、ローコードかつ設定ベースでデータサービスを構築できるようにします。これにより開発の複雑さと難易度が大幅に軽減され、開発部門以外の従業員でも自分のニーズに応じたデータサービスを構成・公開できるようになりました。これにより、新たなメトリクスの開発時間は2日から30分へと大幅に短縮されました。
また、UDataメトリクスサービスプラットフォームにより、エンドユーザーは既存のメトリクスを検索したり、新しいメトリクスを定義したりすることが可能になりました。JDLの歴史上初めて、メトリクスが再利用可能なアセットとなったのです。これを実現したのがStarRocksです。StarRocksはワイドテーブルおよび多表JOINに対応した高性能なクエリ機能を備えており、リアルタイムインジェストと柔軟なデータモデルにより、ストリーミングデータに対するリアルタイム分析も可能にします。
StarRocksを基盤とするUDataプラットフォームにより、JDLは従来抱えていたデータサイロ型アーキテクチャから脱却し、データとアナリティクスサービスを一体化した強力な統合基盤の構築に成功しました。
クエリ性能
StarRocksは、ワイドテーブルおよび多表JOINクエリにおける優れたクエリ性能により、リアルタイム処理とバッチ処理の両方に対応する統合クエリエンジンとして機能します。
リアルタイム分析と更新可能なデータの処理
更新可能なデータとは、変更が必要なデータを指します。JDLでは、クライアントによる出荷オーダーの更新が頻繁に発生するため、データは常に変化しています。
しかし、これまでのデータパイプラインでは、更新レコードの処理は大きな課題でした。
Elasticsearchは以下の理由から、更新データの処理に適していませんでした:
ClickHouseでもリアルタイムの更新処理に課題がありました:
StarRocksは、リアルタイムで更新可能なデータを高性能かつスムーズに処理できる唯一のソリューションであり、JDLのUDataプラットフォームにとって理想的な選択肢となりました。
StarRocksによるフェデレーションクエリ
従来のシステムで既に要件を満たしていた分析処理については、JDLは移行時にそれらを破棄する必要はありませんでした。StarRocksのフェデレーションクエリ機能により、JDLはUData上ですべてのクエリエントリーポイントをStarRocksに統一しつつ、既存のクエリ実行処理をそのまま活用することができました。
オープンソースへの参加
StarRocksのソースコードはGitHubで公開されているため、JDLはStarRocksのユーザーおよび開発者コミュニティ全体にアクセスでき、サポートを受けることが可能です。また、JDLのチーム自身がStarRocksのソースコードをカスタマイズし、機能改善のコントリビューションを行うことで、プラットフォームに最適化された、より強力で進化し続けるクエリエンジンを実現しています。
今後の展望(JD Logistics)
JDLは今後もCelerDataおよびStarRocksコミュニティと連携し、プロジェクトの強化を進めていく予定です。現在取り組んでいる主な強化項目は以下の通りです:
- より多くのデータソースへの対応
- 複数クラスタ間でのフェデレーションクエリ対応
- システムの安定性を高めるためのリソース分離の強化