
Iceberg supports ACID transactions, ensuring data integrity and reliability even in complex, concurrent data operations

What is Apache Iceberg?
Apache Iceberg is an open-source table format designed to manage large-scale datasets in data lakes. It was developed to address some of the limitations of existing table formats like Apache Hive, particularly in handling large amounts of data efficiently and consistently.

Reliable Data Consistency
Non-Disruptive Schema Evolution
Iceberg allows schema changes to be applied incrementally, meaning you can add, remove, or rename columns without impacting ongoing operations.
Improved Query Performance
With features like data pruning and partition awareness, Iceberg significantly reduces the amount of data scanned during queries, leading to faster queries, especially on large datasets.
Iceberg Use Case - Gaming
Modern games produce massive amounts of data; storage plays a crucial role in not only keeping the cost low but also eliminating data silos so everyone can take full advantage of the data across teams and even studios.
Learn how Tencent Gaming reduces storage costs by 15x while eliminating all pre-aggregations through unifying all workloads on Apache Iceberg. Read the case study.

Apache Iceberg Alternatives
Iceberg not for you? Check out these other popular options for open lakehouse table formats.

Apache Hudi
Known for its real-time data ingestion and upsert capabilities, Hudi excels in scenarios requiring low-latency data updates and fast data ingestion with support for incremental data processing.
Apache Paimon
Paimon offers strong support for real-time streaming data and dynamic schema evolution, making it a good choice for environments where continuous data updates and schema changes are frequent.

Delta Lake
Delta Lake is widely recognized for its strong ACID transaction support and seamless integration with the Apache Spark ecosystem, making it a powerful choice for those already invested in Spark for large-scale data processing.
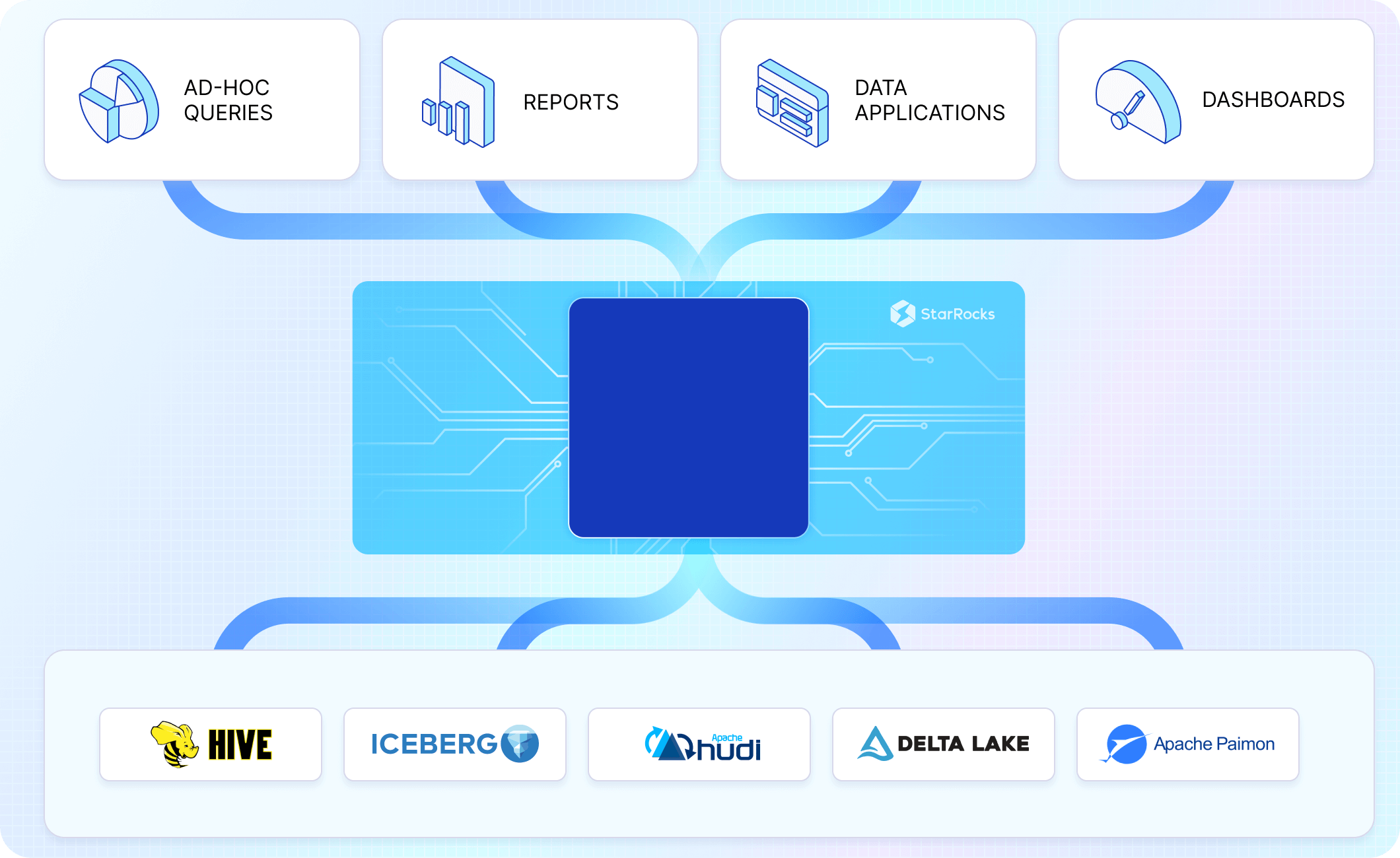
Upgrading Your Query Engine
To fully realize Apache Iceberg's potential, pairing it with a high-performance query engine like CelerData is crucial. CelerData is optimized for a data warehouse-like workload, enabling low latency queries, handling 10s of thousands of concurrent features, and with specific features built just for Apache Iceberg, ensuring you get the most out of your data lakehouse architecture.
Use Cases: Query Engines for Data Lakes
Adopting Iceberg can be a great first step towards building a world-class lakehouse architecture, but rhe right query engines can also make or break your lakehouse's changes of success. Here are several examples.
SOCIAL
A leading social media company has shortened its development cycle and improved cost-effectiveness for its trillions of daily records of data by switching to a data lakehouse architecture.

TRAVEL
Trip.com has ditched its data warehouse with a data lakehouse query engine and is now experiencing 10x better query performance.

E-COMMERCE
An environmental production company 10xed the cost-effectiveness of its analytical system by switching to a modern open-source data lakehouse query engine.
SOFTWARE
Tencent's AB testing SAAS platform ABetterChoice is unifying its demanding customer-facing workloads on the data lakehouse.