

JD.Com X StarRocks
Challenges
To power its operations, JDL developed a sophisticated platform supported by technologies including 5G, artificial intelligence, big data, cloud computing, and the Internet of Things. On top of this platform, it built a smart logistics system to enable automated services, digitized operations, and intelligent decision-making.
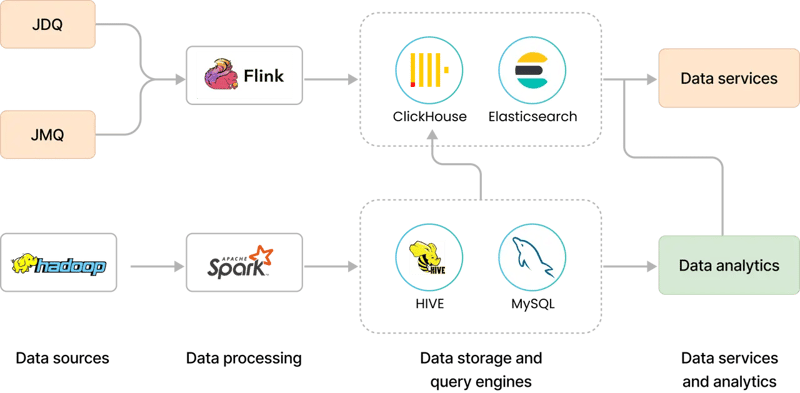
Within this platform, there are two major pipelines:
-
Real-time data is ingested through JDQ (a Kafka implementation) or JMQ, then processed by Flink. Processed data is stored in ClickHouse and/or Elasticsearch, which provides OLAP query capabilities to data services and analytics layers.
-
Batch data is stored in the data lake (HDFS) and processed by Spark. Spark's processing results are stored in Hive or MySQL, which are then queried by the analytics layer.
Siloed Data Services
At JDL, each new project traditionally resulted in the creation of its own data service layer. Data services were not developed with reuse in mind, leading to duplicated efforts that made it difficult to benefit from economies of scale.
Real-Time Data Updates
The nature of JDL's business requires real-time decision-making, hence their analytics platform needs to be able to process updates such as canceled or updated orders in near real-time. Traditional offline processing systems cannot support modern real-time business scenarios like this.
Maintenance Nightmare
Maintaining these data services was also a nightmare. This was especially true during the holiday season. Managing hundreds of data services without consolidated monitoring, traffic control, and disaster recovery functionalities added unnecessary stress to an already overworked DevOps team.
Growing Business Demands
Data engineers were constantly dealing with requests from various business units to prepare data for them. Most of these tasks were tedious and repetitive work.
Data was Hard to Find
It was very difficult for end users to find the datasets they needed. Even when they could find data that seemed to meet their requirements, it was hardly usable due to a lack of clear and consistent metadata definitions.
Data was Hard to Use
Data was stored in different systems, making it difficult to use. This forced many analysts to download the data they needed into Excel for analysis, which was time-consuming and posed a security risk.
Query Speed was Low
Many queries would take tens of seconds, or even minutes, to finish. Slow query speeds disrupted user workflows, lowered productivity, and frustrated users.
Multiple Query Engines
Each system had its own query engine with its own SQL syntax. This made it very difficult to implement a federated system that could query multiple source systems.
Moving Away From ClickHouse - A Unified Metrics Service Built on StarRocks-Generation OLAP Layer
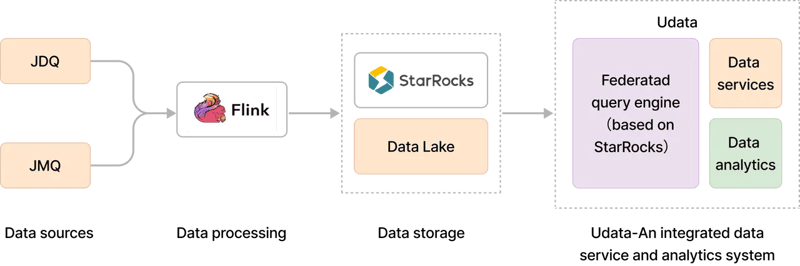
To address these pain points, JDL developed a new metrics service platform called UData.
UData abstracts the process of generating metrics and enables data services in a low-code, configurable way. It greatly reduces the complexity and difficulty of development, allowing non-R&D employees to configure and publish data services based on their own requirements. This has shortened the development time for new metrics from two days to 30 minutes.
Query Performance
StarRocks serves as the unified query engine for both real-time and batch workloads, thanks to its great query performance on wide tables as well as multi-table joined queries.
Real-Time Analytics with Mutable Data
Mutable data means data that needs to be updated, and JDL's data is constantly changing since clients frequently update their shipping orders, but handling updated records had been challenging using the previous data pipelines.
- Bad aggregation query performance.
- Elasticsearch only supports some SQL functions, it is not efficient at handling complex business logic.
- Elasticsearch's maintenance job triggers compaction jobs which can slow down the system's normal read/write operations.
- Bad query performance when dealing with updated records.
- Since ClickHouse doesn't support joined table queries well, it creates more data silos.
StarRocks was the only solution that could smoothly process mutable data in real-time without sacrificing performance, making it the ideal solution for JDL's UData platform.
Federated Queries with StarRocks
In cases where there were existing analytics workloads that were able to meet users' needs under the old system, JDL didn't have to throw away what was already working when they moved on to the new platform. Instead, because of StarRocks' federated querying capabilities, JDL was able to consolidate all query entry points to StarRocks on UData while leaving query executions unchanged.
Open Source Participation
Since StarRocks' source code is publicly available on GitHub, this gives JDL access to an entire community of StarRocks users and developers when they're in need of help. This also provided JDL's team with the opportunity to modify StarRocks' source code and contribute enhancements to the project. The end result was an even more powerful, and ever-improving, StarRocks query engine for their platform.
What's Next for JD Logistics?
JDL plans to continue working with CelerData and the rest of the StarRocks community to enhance the project. Some of the features they are working on include:
- Support for more data sources.
- Federated queries across multiple clusters.
- Enhanced resource isolation to improve system stability.

Download the complete case study