


Join StarRocks Community on Slack
Connect on SlackThis article was originally posted by Pinterest on their engineering blog. You can read the full article here. Credit to: Kapil Bajaj; Sr. Manager, Engineering | Zhenxiao Luo; Sr. Staff Software Engineer | Yi Yang; Sr. Software Engineer | Saahil Barai; Software Engineer I | Ming-May Hu; Software Engineer I.
Introduction
Pinterest is a visual discovery platform where people can find ideas like recipes, home and style inspiration, and much more. The platform offers its partners shopping capabilities as well as a significant advertising opportunity with 500+ million monthly active users. Advertisers can purchase ads directly on Pinterest or through partnerships with advertising agencies. Due to our huge scale, advertisers get an opportunity to learn about their Pins and their interaction with Pinterest users from the analytical data. This gives advertisers an opportunity to make decisions which will allow their ads to perform better on our platform.
At Pinterest, real-time insights play a critical role in empowering our advertisers and team members to make data-driven decisions. These decisions impact campaign performance, our experiments’ performance, and our policies such as rules to catch spam. We have been using Druid to store and provide these real-time insights, but as our scale and requirements continue to change, we have been evaluating different storage options. In the end we decided to migrate this data to StarRocks.
In this blog post, we’ll discuss and share our experience of launching our Analytics app on StarRocks. In the past, we have published our thoughts on using Druid and the benefits we have gotten from it. This post highlights the need for a new system as our scale and requirements have changed over time.
Our Requirements
Our previous setup was running smoothly for us for a few years, and we could scale to hundreds of machines. But over time our scale and requirements increased, and we decided to target the following prerequisites:
-
Keep our costs low while our scale continues to increase to ensure that we provide an efficient solution to our internal teams.
-
Support standard SQL types and schemas, which is the most preferred interface for our users.
-
Support joins, sub-queries, and materialized views, which unlocks a lot of options for our users.
-
Simplify our ingestion pipeline by removing external dependencies like MapReduce jobs, which makes the onboarding and usability less cumbersome.
We evaluated multiple storage options and finally settled on StarRocks because it bridged a lot of gaps we were seeing in our current set up:
-
It has a standard SQL interface and supports joins, sub-queries, and full SQL functionality with impressive performance.
-
It has native ingestion support with no external dependencies.
-
It has an active and supportive open source community of several thousand members.
-
In our tests, it showed performance & cost improvements over our current set up as well as some of the other systems we evaluated against. It was able to perform fast JOIN queries on-the-fly at scale, reducing the need for extensive denormalization pipelines.
What is StarRocks
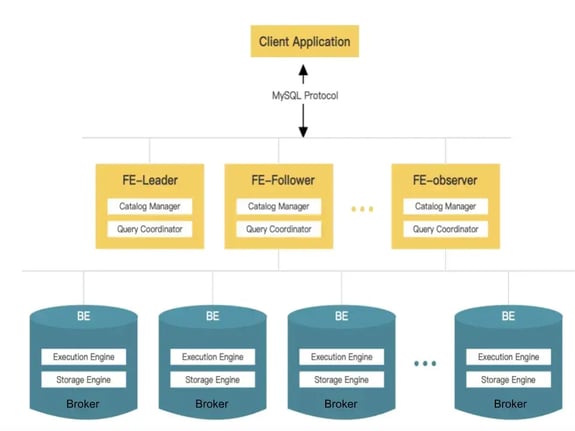
StarRocks is a real-time OLAP database that is capable of handling high-concurrency OLAP workloads, which is useful for customer-facing analytics. Since it’s MySQL compliant, we could easily plug it with any of our existing tools. StarRocks stores data on its local disk and could also query external data in HDFS or S3. It is made up of two components — frontend and backend. Frontend compiles SQL into execution plans and backends executes these plans.
Production Performance
We decided to use Partner Insights, a tool we’ve provided to our advertisers to get real-time insights through customizable dashboards, as our first use case to be migrated to StarRocks.
Figure 1. Pinterest Partner Insights visualization example
Advertisers can log into Partner Insights and learn about the performance of their advertisements based on various customized metrics. These insights allow marketers to understand the effectiveness of their advertising strategies and make quick, data-driven adjustments. The more effective an advertising campaign, the more likely an advertiser will get a higher ROI on investing in Pinterest as a platform.
Figure 2. Pinterest Partner Insights dashboard example
The Challenges
The challenges in offering Partner Insights are multi-dimensional, both figuratively and literally. On one hand, Pinterest serves a massive number of advertisers, each with their unique needs and metrics. On the other, these metrics aren’t just single-dimensional data points; they span multiple dimensions that need to be aggregated in real-time. Given the platform’s customizability, advertisers can choose from a myriad of metrics and tailor their dashboards to fit their specific goals. This ability to customize comes with its own set of complexities — each dashboard can have multiple metrics that need real-time, on-the-fly aggregations across various dimensions.
The flexibility of Partner Insights is both its strength and its challenge, which demands a database solution that can handle a high volume of complex, multi-dimensional queries without sacrificing speed or accuracy.
Implementation
Figure 3 showcases the internal architecture of Partner Insights using StarRocks. The architecture consists of:
-
Front End (FE) nodes: StarRocks FE nodes that are in charge of metadata management and query planning.
-
Back End (BE) nodes: StarRocks BE nodes that persist data and perform data scanning and query execution.
-
Archmage: a Pinterest service built to shield users from the complexities of deployment, version upgrades, and other operations for the StarRocks cluster, while also translating thrift calls into SQL calls for StarRocks. This is a service created to provide a uniform interface over different analytical storage systems.
-
Load balancer: This distributes queries among four StarRocks FE followers using a round-robin method rather than overloading a single follower to maximize concurrency.
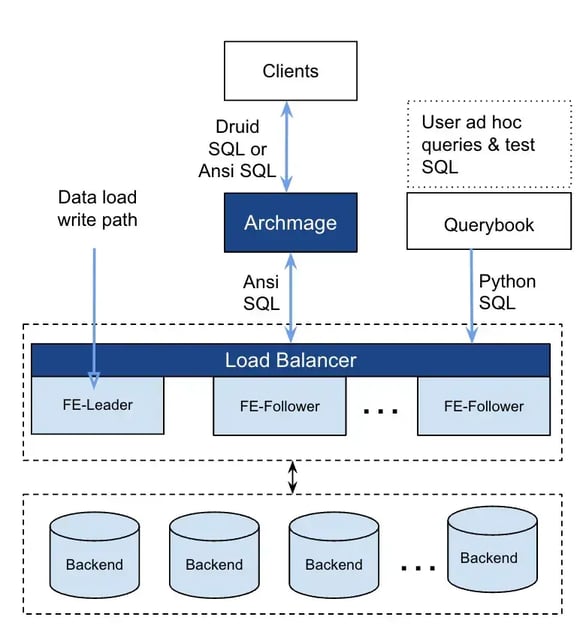
Figure 3. Partner Insights architecture
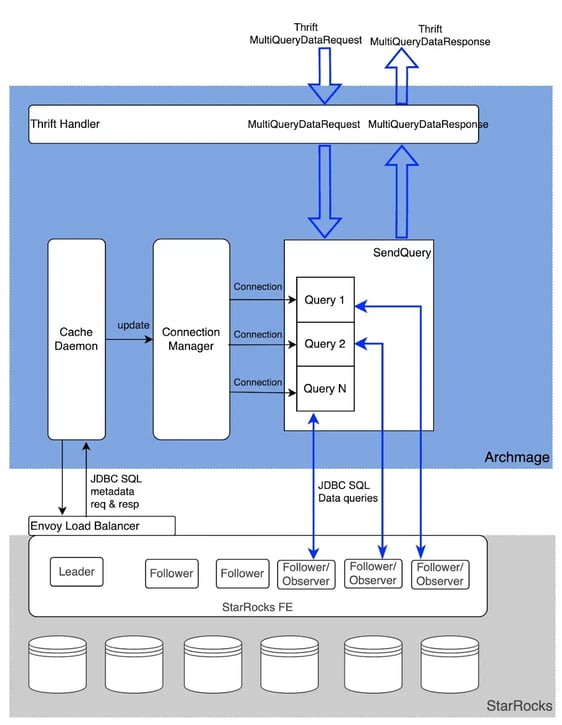
Figure 4. Archmage internals
We used connection pooling in Archmage to decrease the cost of each connection, which minimized the setup time for JDBC connections by maintaining a fixed pool of connections ready for use, thus providing immediate access to a connection for each user request. This optimization saved us an average of 50 ms for each JDBC connection. Currently, each cluster is configured with 70 Backend Engines and 11 Frontend Engines & Observers on AWS R6id.8xlarge instances, each equipped with 32 cores, 256GB of memory, and 1900 GB SSD storage.
Results
After this migration to StarRocks, we observed multiple improvements. The migration reduced the p90 latency by 50% with only 32% of the instances required by the previous set up. This resulted in a 3-fold increase in cost-performance efficiency. The data ingestion process was also streamlined, achieving a data freshness of just 10 seconds.
Additionally, we were able to eliminate JSON configs for data ingestion, as we used ingestion through SQL (which is possible in StarRocks). This streamlined the process of customer onboarding, saving significant labor resources.
Future Works
While the performance gains with StarRocks have been significant, there’s still a lot of room for optimization. Currently, all operations rely solely on StarRocks’ raw query performance, without leveraging features like query cache or materialized views. We are exploring these functionalities to further optimize the system for our high-concurrency workload.