


Join StarRocks Community on Slack
Connect on SlackFounded in 2009 as an affiliate of SF Express, SF Technology is committed to creating the best "brain" for logistics operations and building smart logistics services. After years of independent research and development, SF Technology has built an integrated big data ecosystem for data collection, synchronization, storage, integration, analysis, mining, visualization, as well as machine learning. Powered by the combination of big data, blockchain, IoT, AI, and infrastructure, SF Technology has rapidly developed its business in express service, warehousing, cold chain logistics, pharmaceuticals, commerce, finance, and other fields of business.
Previous Big Data Platform in SF Technology
Previously, SF Technology primarily used Elasticsearch, ClickHouse, Presto, and Apache Kylin™ in its OLAP systems.
- Elasticsearch is the most popular OLAP database in SF Technology and with the help of inverted indexes, Elasticsearch is guaranteed high efficiency and simple operation and maintenance. At present, it is mostly used to conduct log analysis and perform conditional retrieval. The most used version so far is Elasticsearch 5.4. The company also uses Elasticsearch version 7.6 in its newly developed business and adds some customized functionalities, including cross-region backups, deployment of K8S containers, data service platform, etc.
- ClickHouse has been introduced in the past two years and used in some important scenarios, such as delivery services. It has gone through digital transformation with K8S containers as a way to facilitate the process of development, deployment, and management of containerized applications.
- Presto is also frequently used by SF Technology to query data in Apache Hive™. Since we have deployed Presto on yarn, we fine-tune the settings of yarns to provide better integration with Presto while making full use of yarn queues.
- Apache Kylin is less frequently used, and so far only has been applied as a pilot project to serve some business activities in the company’s financial department.
Pain Points in Previous Big Data Platform and OLAP Product Selection
Pain Points in Big Data Platform
Through container orchestration, construction and customization of data analytics platforms, SF Technology has already solved some prominent and common problems on the platforms. But the following problems still remain unsettled.
It is difficult to upgrade OLAP products because different versions of OLAP products might not be compatible with each other. Due to historical reasons, there are multiple versions of OLAP products running online at the same time, which might not be compatible with each other. However, users are unwilling to upgrade the versions of OLAP products as long as their business can still run online. As a result, upgrading versions of OLAP products remains a mission unaccomplished.
Users continue to use existing OLAP products which might be unsuitable for data processing and applications in new business scenarios. In practice, users with only a limited understanding of OLAP products will select OLAP products unsuitable for some data analytics scenarios. For example, users might utilize Elasticsearch to conduct massive amounts of data aggregation, choose Presto to create dashboards, use Apache Kafka® to process batched data.
Operating and maintaining OLAP products becomes a challenge. Because each OLAP product has developed quite different operation and maintenance methods, users and operators are expected to have a good command of knowledge about how to operate and maintain those products.

OLAP Product Selection
There are various OLAP products in the market, so users need to understand the features of those OLAP products in order to select the most suitable ones.
SF Technology has summarized its requirements for OLAP products as follows.
- Powerful competencies without obvious defection.
- High-quality services, such as stability, anomaly detection and solutions.
- Quick response to demands and major production environment problems.
- Flexibility and high potentials.
- Low maintenance cost.
SF Technology has measured the performance of some mainstream OLAP products, according to the aforementioned requirements.
- Performance of OLAP databases in benchmark testings, such as ClickHouse, Presto, Apache Doris、StarRocks.
- Performance of join queries on over one billion pieces of data in medium-sized business scenarios.
- Abilities to conduct SQL queries against ten billion rows of data to support the company’s delivery services.
- Evaluation of other functions: massive data ingestion, joins on large tables, and resilience to failovers.
From the results of evaluations, SF Technology is satisfied with the performance of StarRocks in terms of the following aspects:
- Stability;
- Professional technical support and quick response to demands and problems;
- User-friendly and powerful maintenance system.
Application of StarRocks
Objectives of StarRocks
StarRocks has been introduced in SF Technology to provide integrated and consistent services for big data analytics. As for data ingestion, StarRocks is used to ingest data from three sources.
- Real-time data and offline data are imported through StarRocks’ native loading methods, such as stream load, broker load, and routine load.
- ETL data from Apache Flink® and Apache Spark™ flows into StarRocks through Apache Flink/Apache Spark connector.
- Data from Apache Hadoop®, Elasticsearch, and MySQL are uploaded into StarRocks using external tables.
Then, StarRocks conducts data analytics and provides results to different data applications through JDBC.
- Big data engineering and platform maintenance.
- Fengjingtai, an interactive BI tool developed by SF Technology.
- Data middle platforms, such as data service, data dictionaries.
- Other business systems that would query against StarRocks.
StarRocks lives up to all these expectations, and provides integrated data analytics services, taking the place of many other OLAP databases in certain scenarios.
- StarRocks, taking the place of Presto, swiftly queries Apache Hive data in response to requests from BI tools.
- As substitutes for ElasticSearch, ClickHouse and Apache Kylin, StarRocks stores data details and aggregate data.
- StarRocks can easily export data for further data processing.
Roles of StarRocks in Big Data Platform
Analyzing Business Data
- Data from delivery services has been uploaded into StarRocks as dark launching.
- Other kinds of business data have also been uploaded into StarRocks, such as data from finance, express, international commerce departments.
- More and more business data will be gradually imported into StarRocks from now on.
Constructing the Integrated OLAP Platform
- StarRocks has already been connected to BI tools used by SF Technology.
- Various StarRocks clusters have been built for different purposes, such as clusters for testing before releasing, shared clusters for production or disaster recovery, private clusters for important business.
- StarRocks has been developing and testing its integration with DataX, Apache Flink and Apache Spark.
- Working with SF Technology, StarRocks has been thinking about ways to collect detailed data to serve data services and data dictionaries on middle platforms.
Use Case
The typical case in logistics will explain how StarRocks supports SF Technology to perform data analytics on massive data from delivery services. Previously, this kind of data analytics was completed by Oracle on a single machine. It needed to handle frequent data updates and provided real-time data analytics. The database was overstretched and overwhelmed when confronted with the challenges of skyrocketing business data. As a result, it was criticized for its performance in availability, data analytics speed, data redundancy, time sensitivity, and so on. So after comprehensive products selection, SF Technology eventually turns to StarRocks to improve the performance and time-sensitivity of data analytics in delivery services. The advantages of StarRocks, such as high availability and autoscaling, have helped the company to tackle business pressures during the Double 11 Shopping Frenzy.
Requirements of Data Analytics in Delivery Services
The requirements of data analytics in delivery services are summarized as follows:
- The bottom line is to support queries against flat tables with about 2000 columns of data for each row and 80,000 TPS.
- Rapid iteration to provide improved performance.
- Storing around 10 billion rows of data for the last three months.
- Supporting the seamless transition of data which is used to generate 2000 sets of reports on BI platforms.
- Exporting data for further data processing.
Data Ingestion
According to the requirements above, StarRocks has optimized SF Technology's big data platform in terms of data ingestion and query performance.
- Tables can be divided by partitioning and bucketing. For example, tables can be partitioned by time (a day, a week, etc), and bucketed based on the hash function of the order column. Our experience tells us that the process of data analytics is most efficient when the number of partitions in Apache Kafka® clusters equals to the number of BE nodes.
- Because flat tables contain data from different business systems, sometimes data updates only involve part of columns in flat tables. Under these circumstances,replace_if_not_null is used to replace the original value if and only if the added value is not NULL.
- Because StarRocks's performance in data ingestion largely relies on row sizes and data aggregation. In order to improve the efficiency of data ingestion, StarRocks decomposes one flat table into two smaller tables. One containing data less frequently updated is called shared table, and the other one including data frequently updated is called private table.
- As for machine configuration, in order to handle frequent writes requests, we have decided to increase the number of drives from 6 to 12 on each machine and consider using SSD in the future. To better cooperate with the vectorized engine of StarRocks, we upgrade CPU core counts from 40 to 80 to achieve high QPS.
- StarRocks can rebalance replicas during machine breakdowns. And we hope in the future StarRocks can also rebalance replicas when disks have been added or deleted.
- StarRocks have provided feasible solutions to problems (such as inefficient data ingestion) caused by too many different versions of data ingestion tasks running in parallel. For example, users can adjust Apache Kafka checkpoints, modify the number of shards, partitions and replicas.
Data Query
- StarRocks can conduct data analytics in response to requests from BI tools to generate 2000 sets of reports after the data have been smoothly imported to StarRocks from previous database systems.
- StarRocks has improved performance in parallel queries and data cache strategies in order to guarantee stability when connecting to BI platforms.
More details about query optimizations.
- Columns most frequently used for searching and lookups are defined as key columns, such as the companies of customers.
- Add bloom filter indexes to increase the efficiency of queries.
- Ordering joined tables appropriately, especially when CBO has not been running.
- When joining two tables, index condition pushdown and redundant fields are used to effectively reduce the internal scan data volume.
At present, data from multiple business systems have been processed by Apache Flink and then written into a new Apache Kafka cluster. StarRocks uses Routine Load to extract data from the new Apache Kafka cluster, achieving Exactly-Once semantics, low coupling, and high availability.
To achieve higher availability, we have adopted dual IDC, double write, and active-active architecture. One example is load balancing, such as using two types of domain names in BI tools and other business applications. As a result, these business applications have gained higher availability through the strategy of domain names and JDBC Connection Load Balancing, providing seamless data migration and resilience to breakdowns.
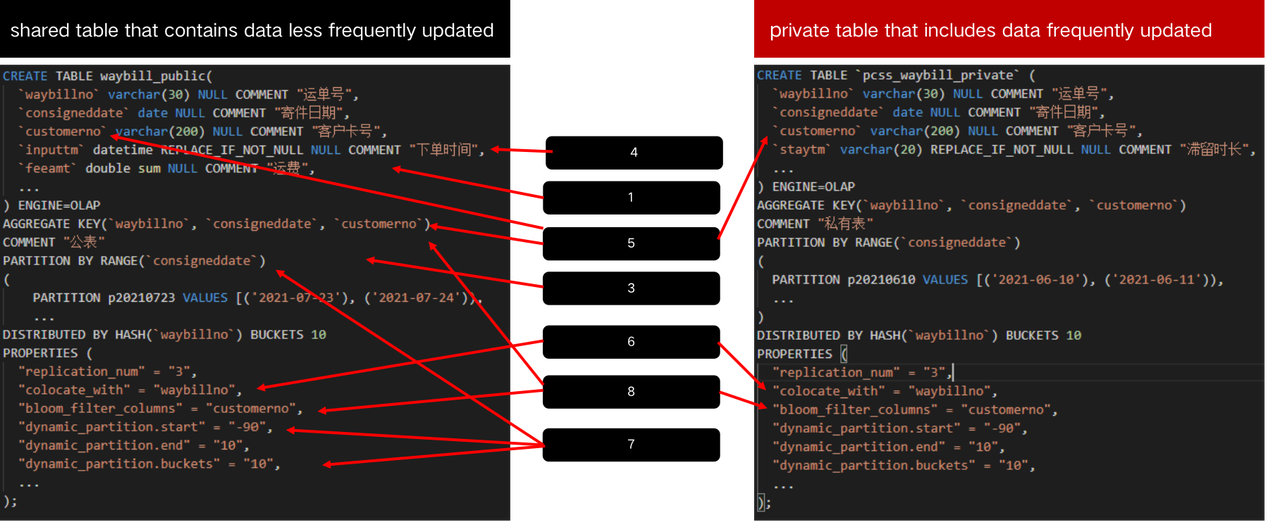
We have summarized table designs that help to improve query performance as follows.
- Aggregate model, duplicate model and materialized views.
- Increasing the number of parallelling data ingestion tasks by dividing one table into two, according to data update frequency.
- Tables are divided by partitioning and bucketing. For example, tables can be partitioned by time (a day, a week, etc), and bucketed based on the hash function of the order column.
- Because data updates sometimes only involve certain columns of tables, Replace_if_not_null is used to replace the original value if and only if the added value is not NULL.
- Fields that are less frequently updated are defined as key columns.
- Collocate Join is used to increase efficiency.
- Dynamically partitioning based on dates, such as a year and a week, and data elimination.
- Bloom filter indexes are added to increase the efficiency of queries.

StarRocks exhibits extraordinary and powerful performance especially in certain scenarios, for example analyzing data less frequently updated, storing 1 billion rows of data, etc. As a result, SF Technology also applies StarRocks in scenarios other than delivery services, such as in the financial system. Previously, the financial system often warned of insufficient resources. After deploying StarRocks, the financial system can function well with only 1/3 of the resources.
Future Plan and Community Building
SF Technology's future plans for OLAP systems are as follows:
- ClickHouse won't provide data analytics services for newly developed businesses of SF technology.
- In 2022, SF Technology intends to deploy StarRocks at a large scale and data from delivery services has already used StarRocks.
- SF Technology hopes to use StarRocks as its data warehouse in cloud.
StarRocks has opened its source code, embracing the limitless possibilities of the unknown future. By operating with StarRocks, SF Technology anticipates building an integrated, swift OLAP analysis platform for all scenarios.
As for end users, this OLAP platform can serve as a one-stop development/operation platform.
- Serverless and measurable resource management.
- High availability in terms of operation and maintenance.
- Data modeling for increasing application scenarios.
- Various database engines provide better support to build an integrated data analytics platform.
- Integration with other applications in the data ecosystem.
We look forward to building an open and energetic community with StarRocks.
Apache®, Apache Spark™,Apache Flink®,Apache Kafka®,Apache Hadoop®,Apache Hive™,Apache Doris,Apache Kylin™and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.