


Join StarRocks Community on Slack
Connect on SlackJSON was never designed for analytics. It’s extremely flexible, universal, and perfect for fast-changing data—but once those JSON logs and events land in your analytical database, it is often treated like a black box. A simple filter like “region = US” can trigger a full scan, burn CPU on string parsing, and keep analysts waiting tens of seconds for answers.
The same qualities that make JSON convenient for developers create headaches for data engineers.
JSON Wasn't Built for Analytics
When JSON becomes the foundation for analytics, its strengths quickly turn into obstacles:
-
Bloated storage: Field names and values are repeatedly stored, leading to high space consumption and poor compression.
-
High query overhead: Accessing fields requires traversing and searching through JSON, resulting in high CPU usage.
-
Schema volatility: Fields can be added or removed at any time, causing inconsistencies in historical data and making data modeling difficult.
-
Type inconsistencies: The same field may appear with different types across records, increasing query complexity.
-
Wide records: A single JSON object often contains hundreds of fields, while queries typically only focus on a small subset.
Start Treating JSON as Structured Data, Not a Blob
Over the years, engineers have tried multiple ways to speed up JSON analytics:
-
Binary serialization reduces string parsing by storing JSON in a compact binary format. It helps somewhat, but still forces queries to scan every record.
-
Manual extraction moves frequently used fields into columns during ETL. Performance improves, but agility suffers—every schema change demands pipeline rewrites.
Both are partial fixes: one lowers CPU costs but leaves queries stuck in full scans, while the other delivers performance at the expense of maintainability. Yet they point to the same underlying principle: stop treating JSON as an opaque blob, and start handling it as structured data that can be optimized for analytics.
The more durable solution is for the database to treat JSON like columnar data automatically. Instead of handling each object as a black box, the system should:
-
Columnarize common fields: Automatically identify and store common fields in a columnar layout, enabling compression, indexing, and pruning.
-
Preserve full flexibility: Retain the complete JSON for less common fields, so agility is not lost.
-
Optimize execution: Apply techniques such as dictionary encoding, late materialization, and global dictionaries, allowing queries to run with efficiency close to native columns.
The principle is simple: separate what’s queried often from what’s just stored, and optimize accordingly.
FlatJSON V2 in StarRocks 4.0
FlatJSON V2 in StarRocks 4.0 puts the “treat JSON like columnar data” approach into practice. It is designed to improve query efficiency without sacrificing JSON’s flexibility. It does this in two ways:
Adaptive storage layout
Instead of treating every JSON object as a single blob, FlatJSON V2 separates fields based on how often they appear:
-
High-occurrence fields are automatically extracted and stored in columnar format, enabling compression, indexing, and pruning.
-
Low-occurrence fields remain in a JSON column, avoiding schema churn and sparse storage while keeping rare or evolving fields accessible without pipeline changes.
Performance optimization
The same techniques that power StarRocks’ native columnar tables are applied to JSON:
-
Zone maps and bloom filters for data skipping
-
Dictionary encoding for compact string handling
-
Late materialization to reduce wasted decoding
-
Global dictionaries for accelerating low-cardinality fields
These optimizations cut both I/O and CPU costs by orders of magnitude. In practice, queries that once took tens of seconds can now finish within seconds.
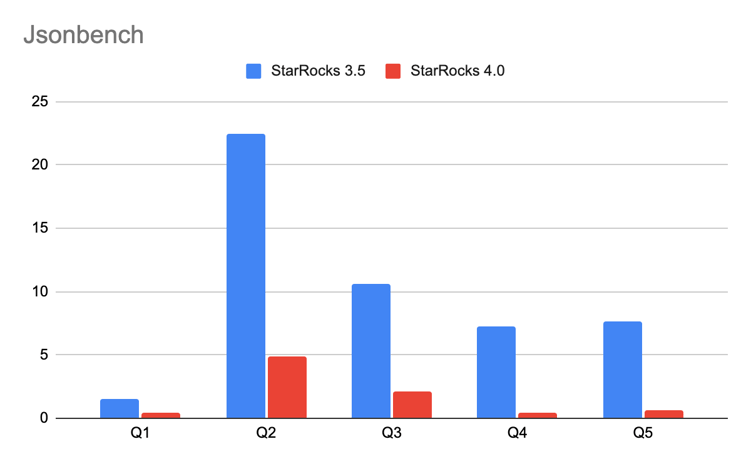
Together, these optimizations move JSON queries much closer to native columnar performance—while keeping ingestion simple and flexible.
How to Use FlatJSON V2 in StarRocks 4.0
FlatJSON is simple to enable—usage is almost the same as the standard JSON type:
-- Minimal table with a JSON column and FlatJSON enabled
CREATE TABLE events_log (
dt DATE,
event_id BIGINT,
event JSON
)
DUPLICATE KEY(`dt`, event_id)
PARTITION BY date_trunc('DAY', dt)
DISTRIBUTED BY HASH(dt, event_id)
PROPERTIES (
"flat_json.enable" = "true", -- enable FlatJSON for this table
"flat_json.null.factor" = "0.3" -- optional: skip extracting too-sparse fields
);
You can toggle FlatJSON per table via a property; newly loaded JSON will be flattened. There’s also a flat_json.null.factor threshold to avoid extracting overly sparse fields.
Load a couple of rows
INSERT INTO events_log VALUES
('2025-09-01', 1001, PARSE_JSON('{
"user_id": 12345, "region": "US", "event_type": "click", "ts": 1710000000
}')),
('2025-09-01', 1002, PARSE_JSON('{
"user_id": 54321, "region": "CA", "event_type": "purchase", "ts": 1710000300,
"experiment_flag": "A" -- rare field, remains in JSON fallback
}'));
Query as usual with JSON functions
The optimizer will turn these into sub-column access when possible, so filters/aggregations can leverage pruning & dictionaries.
-- Filter + group on fields that FlatJSON likely extracted (high-occurrence)
SELECT
get_json_string(event, '$.event_type') AS event_type,
COUNT(*) AS cnt
FROM events_log
WHERE
get_json_string(event, '$.region') = 'US'
AND get_json_int(event, '$.ts') BETWEEN 1710000000 AND 1710003600
GROUP BY event_type;