


Join StarRocks Community on Slack
Connect on SlackStarRocks (SR) is a SQL query engine that delivers data warehouse performance on the data lakehouse. SR is an excellent analytical engine equipped with powerful features, such as a vectorized execution engine, a cost-based optimizer, data cache, and materialized views (MV) with transparent query rewrite capability. Apart from its self-managed proprietary table format, it supports directly querying most data lake table formats, such as Hive, Iceberg, Delta Lake, and Hudi. With its built-in catalog capabilities, one can immediately deploy SR and query data lake tables with just one create external catalog SQL.
At Shopee, we have embraced SR across various platforms, leveraging its capabilities to address a spectrum of analytical needs. In this article, we’ll delve into how StarRocks has been instrumental in transforming our data landscape across three distinct scenarios:
-
Data Service – Building a low-cost and high-speed external data lake.
-
Data Go – Accelerated table joins and insight extraction.
-
Data Studio – Opting for StarRocks Over Presto for faster queries and resource savings.
Data Service X StarRocks
Data Service is a platform at Shopee designed to facilitate data conversion into APIs and manage the entire API lifecycle. With Data Service, users can select desired Hive tables and columns, configure filtering conditions, and create APIs effortlessly. Data Service generates queries on the backend based on the user's configuration. When users trigger the API, the data service runs the query and returns the requested data to the user. However, when the query is too complex, Presto may take minutes to hours to complete query execution; sometimes even taking forever.
Data Service Using StarRocks to Achieve OLAP Acceleration
Here’s why we chose StarRocks:
-
StarRocks supports queries on external Hive tables in production.
-
StarRocks supports building materialized views based on external Hive tables.
-
Using StarRocks MV on external Hive tables helps users avoid maintaining a real-time or near-real-time ingestion pipeline from external Hive tables to the StarRocks internal tables. This lowers human resource development costs, and the component costs required for a real-time pipeline. Additionally, this approach has no impact on users' usage; they don't need to do any work to benefit from the performance improvement in API queries.
Other engines such as ClickHouse can also utilize materialized views for precomputing queried data. However, ClickHouse has limited support for data lakes, and there are no plans for it in its community roadmap. This means that implementing OLAP-like functionality with ClickHouse requires manual API development or transferring Hive data to ClickHouse for precomputation using ClickHouse MVs. Alternatively, one can use Flink to implement real-time precomputation logic and then write the results to ClickHouse. Regardless of the approach chosen, it requires significant manpower support and incurs costs for ETL pipeline components.
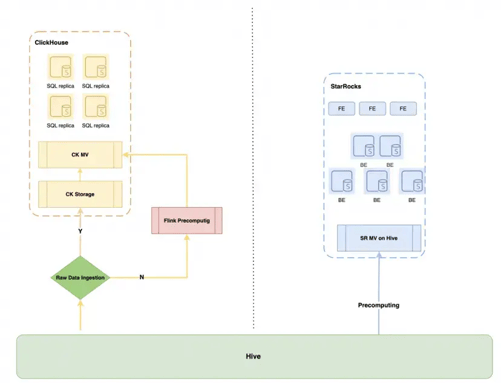
OLAP Acceleration With Materialized Views
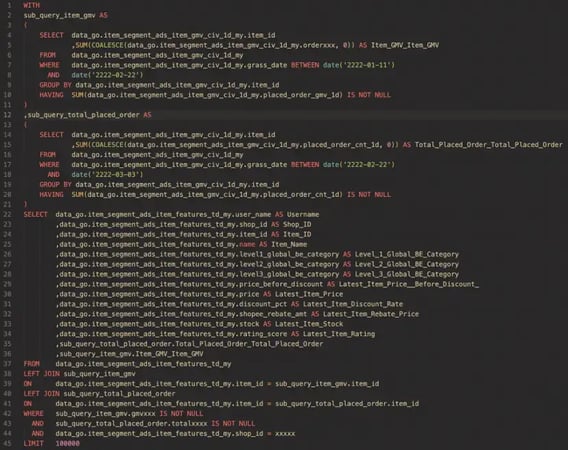
Data Service leverages StarRocks to accelerate queries. We call this feature “OLAP-speedup”. Using the query below as an example, Data Service re-wrote the user's SQL into an OLAP-speedup query. The SQL within the 'With' statement is called a Common Table Expression(CTE).
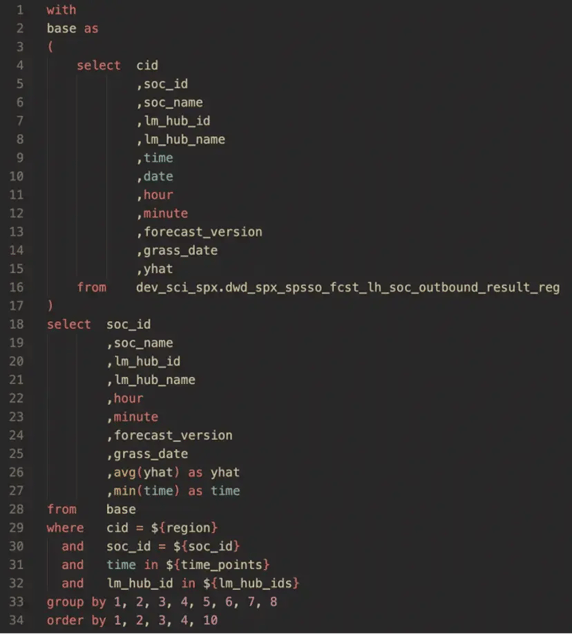
Data Service builds the CTE part of user queries on StarRocks materialized views. By referencing these materialized views, the database engine can swiftly retrieve precomputed results, significantly enhancing query speed.
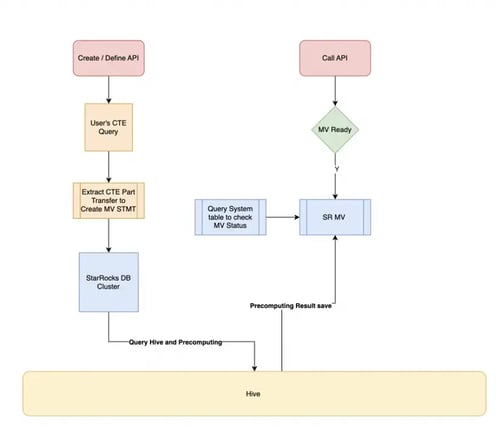
OLAP Acceleration Query Benchmarks
This optimization resulted in queries executing 10 to 2000 times faster, reducing resource consumption and improving overall efficiency.
-
The data service now plans to launch 10 high-traffic APIs, accounting for 70% of the total platform traffic. 5 of them are already online.
-
Based on the API query response time of these 5, our OLAP speedup solution is already breaking records.
The following table shows the execution time statistics for the data service APIs. Currently, these 5 APIs are run once through Presto querying Hive and once querying through StarRocks materialized views. This allows for a visual comparison of the p90 and p99 execution times for both methods.

In the chart above, the second column, query_count, represents the number of times the current API was called within the selected time window (24 hours). The third column, result_consistency_ratio, indicates the comparison between StarRocks' accelerated results and Presto direct querying of Hive results. The low accuracy of the 5th API is due to the fact that its storage table is updated hourly, while the marker is set for daily updates. The refresh of StarRocks materialized views depends on the marker configuration. The fourth and fifth columns show the query latency p99 and p90 respectively after using StarRocks materialized views for acceleration. The last two columns represent the performance improvement of using StarRocks MV versus Presto on Hive for queries at p90 and p99. Lastly, how can StarRocks improve query performance of some APIs more than 1000x? StarRocks executes faster within a given timeframe, while Presto is slower and tends to queue, resulting in a significant portion of API calls' latency being spent in queuing.
Evaluating Resource Usage
In the OLAP acceleration scenario for Data Service, StarRocks supports materialized view acceleration based on external storage, which means it will pull the precomputed data from Hive to the local SR storage during the materialized view refresh, based on the calculation logic of the materialized view. This provides ETL and precomputation capabilities. Whether it's the business users utilizing the data service platform or the developers of the Data Service platform, there's no need for additional labor to maintain a real-time writing pipeline. This significantly saves labor costs as well as the component costs of ETL tasks required by the real-time pipeline.
Data Go X StarRocks
Data Go is a codeless query building platform which supports business users who need to retrieve data of specific metrics (e.g. shop performance, GMV of orders, etc.) from their accessible data models. The data models are created by the data admin by adding one or more tables and/or columns into the data model. Data users can choose their desired data models, build queries by selecting output columns, and apply filters. Upon the user triggering the queries though the UI, Data Go utilizes its Presto engine to retrieve data and download data into a csv file for users. However, when extracting data from multiple tables, the performance of multi-table join queries can be challenging to optimize, often resulting in increased resource consumption and query execution time.
Data Go Uses StarRocks to Boost Join Queries
StarRocks is the best analytical engine for join table queries, as it's embedded with a cost-based optimizer. The optimizer is unique and purpose-built for StarRocks’ vectorized execution engine. This enables StarRocks to execute query execution plans rapidly and cost-effectively and deliver better multi-table join query performance than competitors.
Join Table Query Performance
Data Go has implemented StarRocks instead of Presto to query join tables. We performed several tests across multiple data models over several countries using both StarRocks and Presto to evaluate performance.
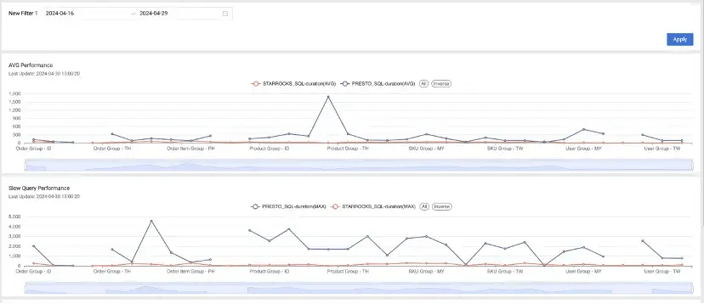
Monitoring the live business scenarios on Data Go, it can be observed that StarRocks delivers a performance improvement of 3 to 10x compared to Presto for queries on external Hive tables.
Zooming into 'Product Group - MY', the sample query based on the product group is showcased below. When executing this type of complex query with Presto, the average time consumed is 364 seconds. In contrast, StarRocks completes the same queries in just 20 seconds. Thus, StarRocks requires significantly less time to execute queries. This efficiency allows StarRocks to process more queries within the same time frame and with fewer resources allocated to each query.
Comparing Resource Usage Between StarRocks And Presto
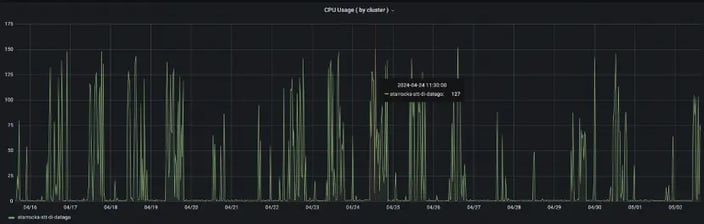
StarRocks Cluster CPU Resource Usage:
-
Peak CPU usage : 150 core
-
Average: 40 core
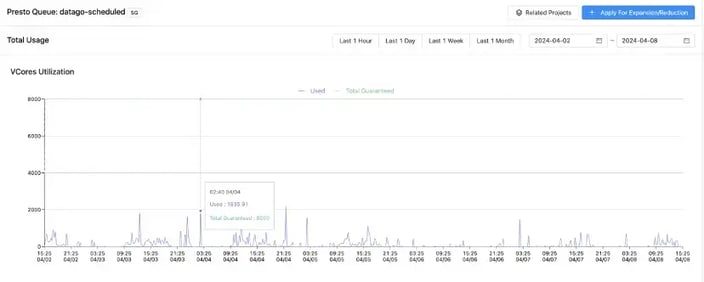
Presto Cluster CPU Resource Usage:
-
Peak CPU usage : 2000 core
-
Average : 100 core
Comparing Resource Usage
Evaluating Data Go's online usage, utilizing StarRocks to query external Hive tables for business operations yields an average performance improvement of 3 to 10x compared to querying Hive with Presto, while simultaneously saving 60% of CPU resources.
These significant performance improvements and computational resource savings can be attributed to two main reasons.
-
The query patterns of Data Go's business is relatively fixed, primarily involving joins across multiple daily updated tables. Our StarRocks cluster supports both in-memory data cache and disk data cache (Data Go's cluster is configured with a 10GB in-memory data cache and a 400GB disk data cache), resulting in a high cache hit rate for Data Go's business queries.
-
StarRocks' self-developed optimizer is more efficient compared to Presto's optimizer. When dealing with complex queries where the execution plan and computation process are the primary time-consuming factors (such as joins and nested subqueries), StarRocks demonstrates significant advantages. In contrast, for queries where I/O is the primary time-consuming factor, the difference between the two is not as substantial
Data Studio X StarRocks
Data Studio StarRocks on Hive
-
StarRocks operates as a powerful query execution engine, offering support for external catalogs such as Hive. Users can leverage StarRocks to directly query Hive tables. With its massively parallel processing (MPP) framework, a single query request is divided into multiple physical computing units, which can then be executed in parallel across multiple machines. Parallel execution of computing units fully utilizes the resources of all CPU cores and physical machines and accelerates the query speed. This architecture makes StarRocks excel in query performance, particularly in handling complex analytical queries involving aggregation, sum, and group by statements.
-
To address Data Studio's current challenges with complex queries, the team sees StarRocks as a potential solution to execute user queries. We are conducting experiments to assess performance and error rates, comparing StarRocks against our existing engine, Presto.
-
StarRocks has mature support for data lakes. This is exemplified thorough its vast collection of enterprise users. This includes Ctrip, which utilize StarRocks to query Hive for generating reports, Xiaohongshu which uses StarRocks on Hive as an ad-hoc query engine, and Tencent which leverages StarRocks for querying and writing to Iceberg, implementing cold and hot data separation, and periodically sinking cold data into Hive.
StarRocks Performance Comparison
Computing Resources
-
StarRocks: 400 core; 2700 GB Memory
-
Presto: 400 core; 2700 GB Memory
Query Benchmarks
-
SQL: Using Data Studio daily ad-hoc queries from 25.03.2024 and 29.03.2024.
-
Query Method: Concurrently stress test StarRocks and Presto with 1, 5, 20, 40, and 50 threads respectively.
-
Latency Statistics: Measure the average latency, p90 latency, and p99 latency for StarRocks and Presto under the corresponding concurrent stress tests.
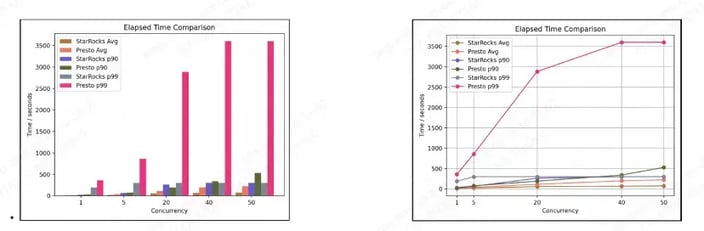
Test Report

Evaluating of Resource Usage
Based on the test results from Data Studio, when utilizing the same computational resources (400core + 2700GB memory), StarRocks demonstrates a performance improvement of 2 to 3x compared to Presto. In other words, StarRocks can deliver comparable computational capabilities to Presto using only 50% of the resources utilized by Presto.
In the context of Data Studio, the primary improvements stem from the superiority of StarRocks' optimizer. The nature of our daily ad-hoc queries in Data Studio can be characterized by a lack of fixed patterns. Instead, it’s more like a collection of complex queries with numerous nested subqueries and joins. This aligns precisely with the query patterns that StarRocks excels in handling. Additionally, due to the unpredictable nature of query patterns in ad-hoc queries, data cache has minimal impact in our Data Studio scenario.
Selecting StarRocks
StarRocks excels in multiple user scenarios, offering high-speed querying from external data lakes, optimized query performance for joined tables, and superior execution speed and resource savings compared to Presto. StarRocks continues to be utilized across our organization, covering Data Service, Data Go, Data Studio and more. It effectively addresses our pain points and optimizes resource utilization for data analytics, making it the ideal solution for our data analytics needs.