


Join StarRocks Community on Slack
Connect on SlackSlow data lake queries often compel users to transfer their data and workload to a data warehouse for query acceleration. This process solves the performance issue but introduces data governance challenges and elevated costs. In this article, we'll examine how data lakes have evolved beyond batch workloads to match data warehouse performance, so we can analyze the data in place.
Pre-computation pipelines are essential in accelerating data lake queries. Building denormalized and pre-aggregated tables with data processing tools like Spark to avoid on-the-fly JOINs and aggregations is commonly practiced. However, these methods are creating challenges for both data engineers and data users.
To benefit from the performance gain's promised by data lake architectures, data users must modify their SQL queries to point to the new tables with pre-computed values, which is extremely tedious. Optimizing this experience for data users is no easy task for platform engineers as well. All needed data pipelines and pre-computations have to be planned before the data users develop client-side applications (writing SQL scripts).
This planning takes extensive testing and often leads to making pre-computed tables that never get used, creating waste in both labor and hardware, ultimately leading to a prolonged development cycle and elevated costs.
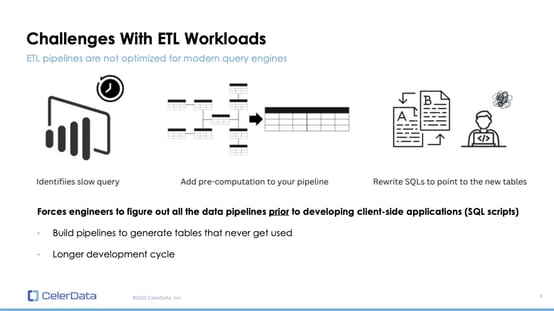
Figure 1: Challenges With ETL Workloads
This mismatch in effort and performance is a result of advancements in query engines that have transformed pre-computation from a standard necessity to an on-demand resource: modern engines, being faster, allow for more on-the-fly computation and reduce the need for extensive pre-computation of operations like JOINs and aggregations.
The Solution – StarRocks Materialized View With Query Rewrite
StarRocks' materialized views are designed for pre-computation to accelerate data lake queries. They can be built from internal or external tables, including those from Apache Hive, Apache Hudi, Iceberg, and Delta Lake. These materialized views can be built from a mix of sources and support both single and multi-table queries.
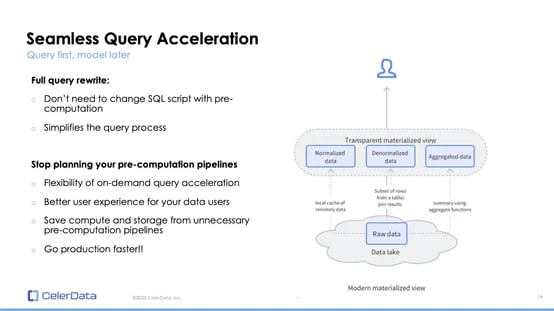
Figure 2: Query Acceleration With Materialized Views
The defining feature of StarRocks materialized views is their ability to automatically rewrite queries: during query execution, StarRocks' cost-based optimizer can rewrite the query to utilize the most efficient materialized view, eliminating the need for users to modify their SQL queries to gain performance benefits.
This addresses the pre-computation challenges previously discussed: all queries can now be run against raw data and on-demand materialized views can be added at any time to fix slow queries. This approach not only offers flexibility but also eliminates the need for extensive pre-computation pipeline design, dramatically shortening the development cycle.
The Proof – Trip.com’s Artnova Platform
Artnova is Trip.com's unified reporting platform that serves all of their business units. Initially challenged by performance issues with Trino, Trip.com found a robust solution in StarRocks that eliminated the need for a data warehouse.
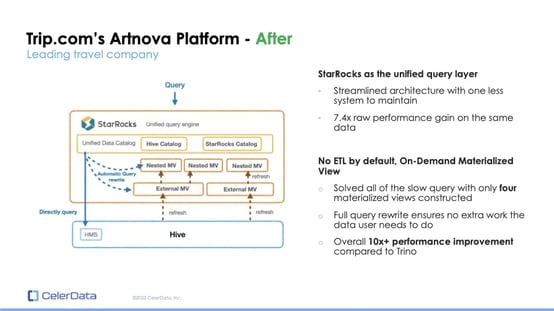
Figure 3: Trip.com's Artnova Platform After Replacing Trino With StarRocks
The key to success for Trip.com lies in the combination of StarRocks' performance and its ability to perform on-demand pre-computation. With only four materialized views created, Trip.com effectively eliminated all of the slow queries, with performance exceeding Trino by more than 10x. This enhancement not only accelerated their data processing but also significantly reduced the operational complexities and labor-intensive tasks previously required.
The Next Step – Try StarRocks’ Materialized View Right Now
StarRocks' materialized views offers a robust solution to accelerate data lake queries. Its automatic query rewrite feature streamlines the development process, enhances performance, and improves the overall user experience. You can learn more about StarRocks' materialized view feature by watching the on-demand webinar above.
If you want to experience accelerated data lake queries and are ready to ditch your data warehouse, check out Celerdata Cloud. Built on top of StarRocks, Celerdata Cloud addresses data lake query challenges head-on with its class-leading performance and features tailored to run modern workloads directly on the data lake. Sign up at cloud.celerdata.com for a free trial.