


Join StarRocks Community on Slack
Connect on SlackPreviously, we examined the growing need for real-time analytics across a variety of common business use cases. We also identified a number of limitations found in popular analytics platforms that have made supporting (or even achieving) real-time analytics difficult. In this article, we’ll delve back into those challenges and explain how they led to the creation of the StarRocks project and how exactly StarRocks makes real-time analytics easy.
What is StarRocks?
StarRocks is a real-time, high-performance cloud-native analytical database that enables real-time, multi-dimensional, and highly concurrent data analysis.
From its inception, StarRocks was designed to make high-performance real-time analytics easy to deliver and maintain, but how does it achieve this? How does StarRocks stand out against other open-source and commercial options on the market today?
In the following sections, we’ll take a look at the capabilities that make StarRocks the top choice for real-time analytics around the world.
Simplified Real-Time Pipeline
Stream preprocessing is a notoriously complex task. Not only does it require an army to keep it running, but it is also a pipeline that is only necessary for real-time analytics scenarios. Introducing it further complicates the technology stack that a team/company needs to manage.
StarRocks has a series of optimizations and features engineered to support doing some preprocessing inside of StarRocks, from ETL to ELT, simplifying the real-time pipeline.
No need for denormalization in the upstream
With StarRocks, there is no need to denormalize data in the upstream process/system, which can save time and effort in managing and using a stream processing tool.
The exceptional JOIN query performance offered by StarRocks enables the joining of tables of reasonable sizes during query execution, without compromising on the overall query performance.
Additionally, this approach preserves the data in its original star/snowflake schema format, providing greater flexibility to the system by enabling lightweight dimension and schema changes from upstream in case of business changes.
Partial update
However, there are more demanding scenarios such as highly concurrent user-facing analytics where, even with StarRocks, denormalization is still necessary. StarRocks' partial update is here for the rescue.
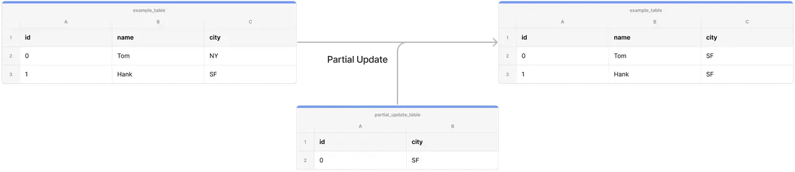
Partial update.
Like the image shown above, just as its name suggests, the partial update allows users to update a row by only providing a few columns. Instead of figuring out how to JOIN 21 tables together in an upstream stream processing job, the partial update feature allows users to update each column separately, taking care of denormalization elegantly without the need for a stream preprocessing application in the upstream.
Real-time pre-aggregation within StarRocks
StarRocks provides an aggregated key table and synchronous materialized view, which performs real-time pre-processing for aggregated queries during data loading. This eliminates the need for pre-aggregation in the preprocessing phase, further simplifying the data pipeline and improving query performance.
 Aggregated table.
Aggregated table.
The aggregated table is a table that aggregates the data automatically during data loading.
With aggregated tables:
-
The aggregation is defined as part of the create table statement.
-
As the data is loaded, the aggregation happens automatically.
-
Granular data is not kept, only the key and the aggregation is kept.
Aggregated tables simplify the preprocessing pipeline by automatically aggregating data during data loading. With aggregated tables, you define the aggregation as part of the create table statement, and as the data is loaded, the aggregation happens automatically. This means that granular data is not kept, and only the key and the aggregation are kept. This feature is especially useful when pre-aggregation is necessary, but granular data is not needed.
Synchronous materialized view (Rollup)
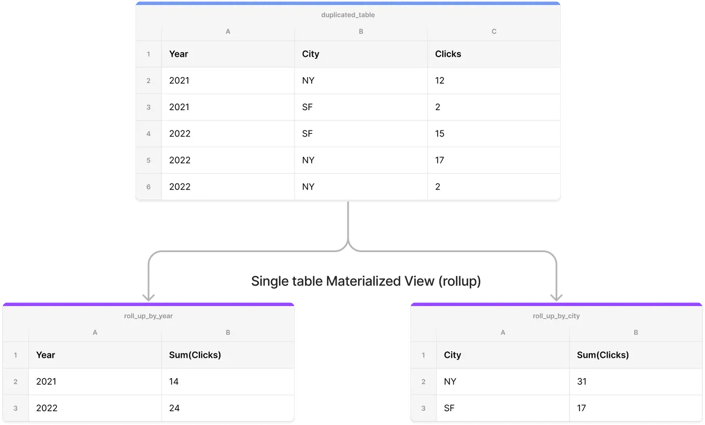
Synchronous Materialized View.
Materialized views (MV) are physical copies of views. StarRocks' synchronous materialized view, or Rollup, is designed to seamlessly accelerate real-time, single-table aggregate queries.
StarRocks' synchronous materialized view supports:
-
Synchronous incremental Update
-
Query rewrite
It supports synchronous incremental updates, which means that the rollup table is updated with each data change of the base table, keeping the rollup in sync at all times. Moreover, the materialized view supports query rewrite, where queries are automatically rewritten by StarRocks' CBO to utilize the MV to boost query performance.
Real-time ELT with StarRocks
In summary, StarRocks eliminates the need for denormalization and pre-aggregation in the upstream process/system, which can save time and effort in managing and using a stream processing tool. StarRocks also enables fast and flexible JOIN and aggregated queries in the database, by leveraging its exceptional JOIN query performance and its aggregated key table and synchronous materialized view features.
These features allow StarRocks to join tables of reasonable sizes during query execution, preserve the data in its original star/snowflake schema format, and perform real-time pre-processing for aggregated queries during data loading. With StarRocks, users can enjoy real-time, multi-dimensional, and highly concurrent data analysis without compromising query performance or system flexibility.
Primary Key Table: Real-Time Upsert With No Compromise
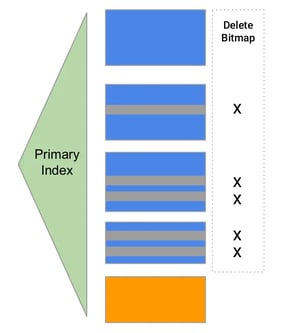 StarRocks Primary Key table.
StarRocks Primary Key table.
The StarRocks primary key table is an efficient solution for real-time analytics for its ability to support real-time update and delete operations without sacrificing query performance. This is achieved by using a unique primary key index, which efficiently handles all upserts and delete operations during data loading, resulting in a single version of data for query processing. By treating all upserts as delete and insert operations with the primary key index, the storage can easily locate the exact location of a row and quickly apply append and delete operations, resulting in only one version of data preserved for query processing.
This approach eliminates the need for the merge-on-read model, which consumes a lot of resources during version merging when querying and blocks predicate push-down and index usage, significantly affecting query performance. By avoiding this model, the primary key table ensures uncompromised query execution, even with frequent data changes, since predicate push-down and index usage remain unaffected.
Moreover, the primary key table enables real-time scenarios, such as fraud detection, that require data freshness in seconds rather than minutes. Overall, the StarRocks primary key table offers significant advantages over the merge-on-read model, making it an efficient solution for real-time analytics with the update and delete operations.
Accelerated Time to Insight Even With Data Lakes
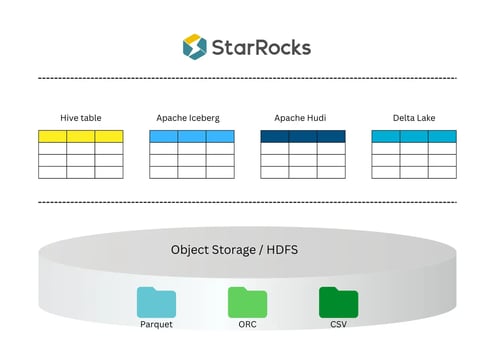 StarRocks data lake analytics.
StarRocks data lake analytics.
StarRocks can also be used as a query layer for the data lake. StarRocks enables seamless integration with data lakes such as Apache Hive, Apache Hudi, Apache Iceberg, and Delta Lake, allowing users to query data lakes directly without data migration and with no added latency. This will further enhance the value of real-time analytics by providing even faster insights.
While having no additional overhead added to data freshness on the data lake, StarRocks offers 3-5x better query performance compared to other solutions, not only shortening the time-to-insight but also providing a better user experience.
Case Study: Airbnb Trust Analysis
Let's next look at the case of an actual user utilizing StarRocks for real-time analytics workload: Airbnb's Trust Analytics.
We will briefly go over Airbnb's case in this article. However, if you want to learn more, make sure to check out the case study and the blog post.
To ensure the legitimate rights and interests of users and the platform, data scientists at Airbnb need to identify violations on the platform in a timely manner to prevent possible losses. This puts forward new requirements for the OLAP system:
-
Real-time update: Business data needs to be obtained at the earliest opportunity and merged with historical data to achieve real-time data landing and query.
Complex queries: Due to the uncertainty of violations, the dataset to query and the query method cannot be predicted. Therefore, the OLAP system must be able to run complex ad-hoc queries on real-time updated data and return results within seconds.
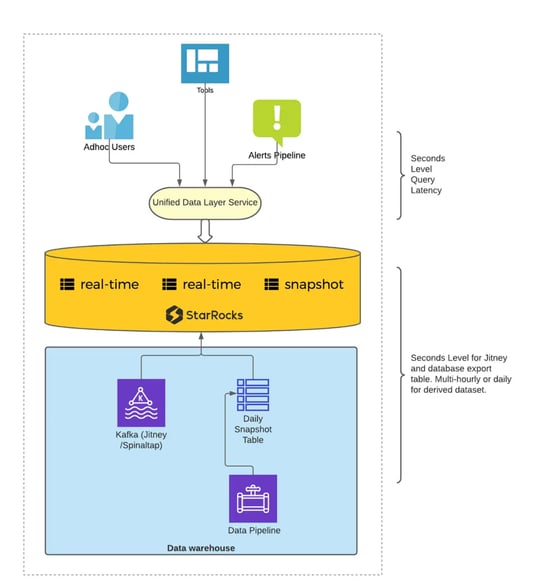 A new StarRocks-powered architecture.
A new StarRocks-powered architecture.
Before using StarRocks, Airbnb used Apache Druid for high concurrency & real-time workloads and Presto for ad-hoc exploratory analysis on the data lake. These previous systems could not satisfy the requirements for trust analysis for the following reasons:
-
Unsatisfactory query latency, especially for complex queries.
-
The query layer could not handle JOIN queries well, denormalization was necessary for all data pipelines. This was extremely inflexible and expensive.
-
Data islands (isolation): Data stored in Apache Druid and the data lake were isolated from each other, creating a data island situation that hinders data integration and analysis.
By adopting StarRocks as their unified query layer:
-
The extreme performance of StarRocks allowed Airbnb data scientists to execute complex ad-hoc queries with latency low enough to be interactive.
-
No more denormalization upstream: With StarRocks' on-the-fly JOIN capabilities, the majority of the tables no longer needed denormalization, making analytics more flexible and cheaper to maintain.
-
Accelerated time-to-insight: The data freshness was brought down to 10 seconds, satisfying the requirements of trust analytics at Airbnb.
-
Unified query layer: StarRocks allowed Airbnb to eliminate its data island. Users can now federate real-time and historical data analytics with ease.
Embrace Real-Time Analytics with StarRocks
Real-time analytics is an indispensable asset for modern enterprises seeking to remain competitive in today's data-driven world. Despite the challenges, innovative solutions like StarRocks are making real-time analytics more accessible, efficient, and powerful, empowering businesses with unparalleled insights for informed data-driven decision-making and overall success.
As companies continue to embrace data-driven strategies, the demand for real-time analytics will only grow. By leveraging cutting-edge solutions like StarRocks, organizations can harness the full potential of their data, gaining a competitive edge in the market and driving growth. In an era where data is the new currency, real-time analytics is the key to unlocking its true value and transforming it into actionable business intelligence.
Experience all of the powerful capabilities of StarRocks by getting started with it for free by downloading it here and joining our Slack community.
If you’d like to see StarRocks in action in minutes without having to waste time with setup, we recommend taking a look at CelerData Cloud which offers a free monthlong trial (as well as a free developer tier).