


Join StarRocks Community on Slack
Connect on SlackThe unrelenting demand for more data to inform business decisions has put data and infrastructure engineers in a bind when it comes to managing an ever-growing volume of data. From managing the pipeline to keeping it running fast, it can leave engineers teams feeling worn out just trying to ensure their users have timely insights. This no longer needs to be the norm.
Here's what you should know if you're facing these challenges.
The last few years have seen various solutions come out designed by engineers who were sick of dealing with the tedious and time-consuming work that comes with good data management and working with extreme data volumes in real time. While there are many solutions worth your consideration, for this article we'll take a look at the StarRocks project, arguably one of the fastest and easiest to work with options available.
What is StarRocks?
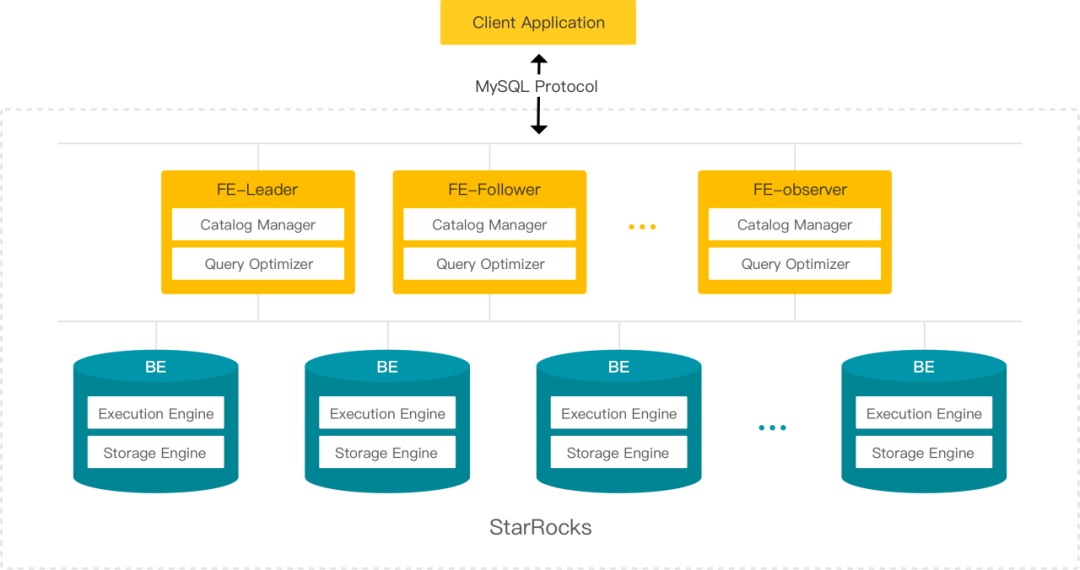
First, what is StarRocks exactly?
StarRocks is an open real-time SQL engine designed specifically for delivering real-time analytics while minimizing the engineering grunt work that real-time analytics normally entails. StarRocks also supports OLAP analysis, customized reporting, ad hoc analysis, unified analysis, and high-concurrency queries, but for the purpose of this article, we're going to focus on what makes StarRock both unique and the leading choice for real-time analytics.
Learn more about StarRocks in the video below:
Make Managing High-Volume Data Easy and Low Cost
When it comes to the challenge of managing petabytes of data with over a hundred nodes, there are two critical issues that need to be addressed: data distribution and parallel computing.
Here's how StarRocks tackles these challenges.
First, StarRocks uses a shared-nothing architecture, meaning data is distributed to each node based on predefined rules. A single node is able to run both storage and computing workloads. This tight coupling enables local computing, reducing network transmission overhead. For Cross-node data computing, such as distributed joins, StarRocks handles this through a massively parallel processing (MPP) framework.
Managing Data with Partition and Tablet Data Distribution
Next, it's worth discussing how StarRocks manages data.
StarRocks is a columnar database system and makes use of partitioning and bucketing to manage data. Data in a table is first divided into multiple partitions and then into multiple tablets. Tablets are the basic logical units of data management in StarRocks. Each tablet can have multiple replicas that can be stored across different nodes.
Partitions reduce table scans, tablets increase system concurrency, and replicas facilitate data backup and restoration, preventing data loss.
You can see an example of this In the following figure. Here the table is divided into four partitions based on time. Data in the first partition is further split into four tablets. Each tablet has three replicas, which are stored on three different backends (BEs).
-1.png?width=1200&name=1280X1280%20(1)-1.png)
StarRocks can schedule one SQL query to all the destination tablets for parallel processing, fully utilizing the computing power of multiple nodes. This also helps offload the query pressure to multiple nodes, increasing service availability. You can add nodes on demand to increase concurrency.
Tablet distribution is not confined by physical nodes. If the number of BEs changes, an automatic migration of tablets will be triggered without requiring manual adjustments. Node changes will not affect ongoing services, allowing for the auto-scaling of clusters.
Additionally, StarRocks uses a multi-replica mechanism for tablets. If one replica is compromised, data can be restored from other replicas to ensure high levels of data reliability.
A Powerful MPP Framework for Efficient and Reliable Computing
The data locality offered by tablets allows for more efficient computing and lowers network transmission costs. But when it comes to cross-node computing, StarRocks employs an MPP framework for parallel queries across multiple nodes, fully utilizing cluster resources.
StarRocks' MPP architecture also avoids creating a single point of failure (SPOFs) that's a common occurrence with many other database systems that utilize a scatter-gather approach.
-1.png?width=295&name=1280X1280%20(2)-1.png)
What You Need for Real-Time Analytics
This is just a taste of the capabilities of the StarRocks project, and if it has you interested, we recommend checking out the project's GitHub page and joining the community. You can also get started with StarRocks right now by downloading the latest version here.
If StarRocks sounds like what you need for real-time analytics, but you're looking to get that same performance with enterprise-ready features, dedicated support, and the ability to deploy in the cloud, then get in touch with us at CelerData. Founded by the creators of StarRocks, CelerData offers a powerful on-premises and cloud version of StarRocks with additional features like GUI-based administration, automated deployment, and a SQL test environment.