


Join StarRocks Community on Slack
Connect on SlackOriginally developed as an internal project by Yandex, ClickHouse has been a market leader in the analytical database sector for years. Yandex open sourced ClickHouse in 2016 and, at the time, it became the go-to solution for companies in need of high-performance real-time analytical capabilities.
In this article, we will take a look at how ClickHouse has risen to the top among other analytical databases, what challenges ClickHouse users face, and why some users are now choosing to migrate away from ClickHouse.
All of the information presented in this article is based on publicly available information* as well as information collected from real former-ClickHouse users who have moved from ClickHouse to other solutions.
What Is ClickHouse?
According to ClickHouse's documentation, ClickHouse® is a column-oriented database management system (DBMS) for online analytical processing of queries (OLAP) (1). This definition provides us with three key pieces of information about ClickHouse:
- It is a database: A database has both a storage engine and a query engine. ClickHouse can efficiently ingest data from various sources and its query engine provides low-latency query responses.
- It is an OLAP database: An On-Line Analytical Processing (OLAP) database is not designed to support normal business transactions. It is specifically designed to analyze large amounts of business records, focusing on reading and computing but less on writing and transaction processing.
- It is a column-oriented OLAP database: Column-oriented storage is the de-facto storage format for analytical databases since analytical queries read large numbers of records but are only interested in a limited number of columns. Columnar storage is much more efficient than traditional row-oriented storage in this scenario.
In essence, ClickHouse provides excellent query performance (think query response times of sub-second or a couple seconds) for complex analytical queries on PB-scale data volumes.
ClickHouse Architecture
ClickHouse is based on a shared nothing architecture. In each node, compute and storage are tightly coupled, although a cloud native architecture in which compute and storage is currently under development. Each node can process data extremely fast since there is no cross network data distribution.
ClickHouse clusters can be easily expanded by adding more servers, which is what gives it the capability to process large amounts of data. Through sharding and replication, data can be distributed across 100s of nodes. Apache ZooKeeper is required for replication.
The following diagram shows how data is replicated in a ClickHouse cluster:
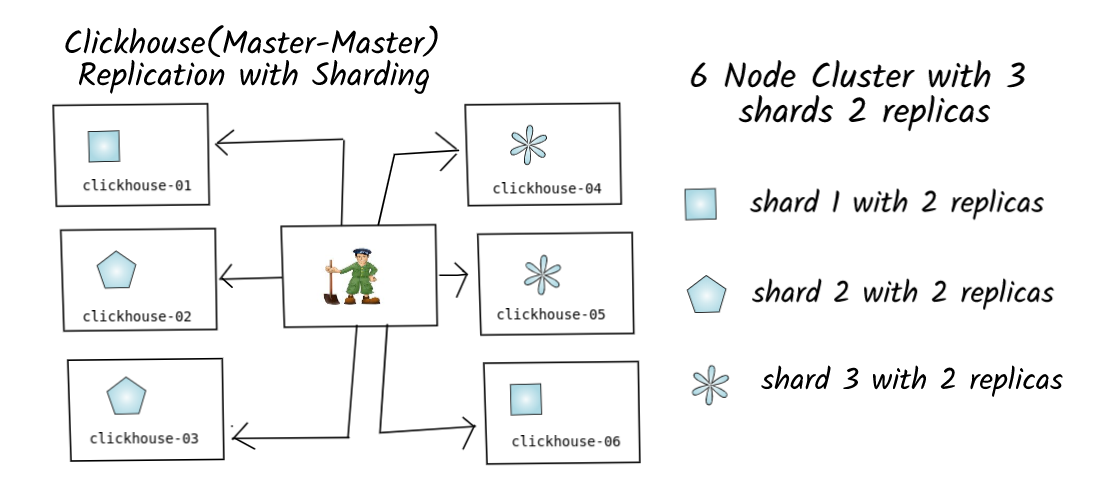
Source: https://aavin.dev/clickhouse-cluster-setup-and-replication-configuration-part1/
Key Features of ClickHouse
Clickhouse offers many great technical features. Some key features include:
-
Columnar Storage - great for analytical queries
-
Ordered Data Storage - further improves data retrieval
-
Primary Key Index and Sparse Index - flexible indexing schema for fast queries
-
Data Sharding and Partitioning - effectively storing large volumes of data
-
High speed ingestion - supports real-time data processing
Use Cases for ClickHouse
ClickHouse is widely used in many analytical scenarios for businesses of all sizes. Some of its more popular use cases are:
-
Fraud detection in financial services, where low-latency queries are critical to identify any fraudulent activities and prevent loss.
-
Hospitality companies leverage ClickHouse to understand the latest booking, pricing, revenue, and property performance information.
-
Manufacturers build logistics planning systems on top of their ClickHouse database.
-
Media and entertainment companies have been using ClickHouse to monitor streaming quality, manage ads placement, and push personalized promotions.
-
SaaS companies use ClickHouse to analyze user and product behaviors to improve sales.
-
Cloud service providers build cloud resource monitoring and network analysis on top of ClickHouse.
Benefits of Using ClickHouse
ClickHouse has many great capabilities that make it one of the most popular and top-performing OLAP databases. While users can find a lot to like with the solution, the most common reasons users adopt ClickHouse are:
Query Performance
Compared to other databases and data warehouses, ClickHouse can be 2 to 10 times faster than most of its competitors, including all the cloud data warehouse products.
Efficient Use of Storage and Compute Resources
In addition to columnar storage, ClickHouse also offers many other great features such as highly efficient data compression, advanced indexing, and vectorized computation. It can fully utilize compute and storage capabilities of modern servers and overall reduces infrastructure costs.
Support for a Wide Array of Use Cases
ClickHouse provides flexible data type support such as JSON, Map, Array, and a wide variety of scientific and statistical calculation functions. This makes it an extremely versatile OLAP database that can be deployed in many different industries.
Limitations of Working With ClickHouse
While ClickHouse has gained popularity around the globe in the past decade, it also has some serious limitations you should be aware of. These limitations include:
-
Support for Joined Tables
-
Number of Concurrent Sessions
-
Processing Mutable Data
-
Cluster Expansion
Let's take a closer look at each of these.
Limited Support for Joined Tables
Join relationships are the foundation of modern analytics theory (such as star schema), but they also pose a great challenge for query performance. ClickHouse has tried to circumvent this challenge by focusing on single-table query performance. Because of this, users have to flatten joined tables into a single table in ClickHouse. This step adds pipeline delay and requires extra resources.
Limited Number of Concurrent Sessions
Modern analytics, especially real-time analytics, provides critical support for executives, front line workers, and, sometimes, AI-powered applications. This is demanding work that requires high-performance queries for 100s or 1000s concurrent sessions. ClickHouse was designed to serve the traditional needs of internal analytical users, which had limited concurrency requirements. Because of this, support for large numbers of concurrent sessions is complicated and can be expensive with ClickHouse.
Processing Mutable Data
Mutable data is a common byproduct of business activities. It can be caused by glitches in the underlying data pipeline, resulting in incomplete or out of order data, or it can be part of normal business logic, such as updated order items. ClickHouse, like most other analytical databases, doesn't support UPDATE and DELETE operations natively. Instead, it provides a MUTATION operation to asynchronously ALTER TABLE.
Cluster Expansion
When an extra node is added to a cluster of ClickHouse, there is often heavy data rebalancing that has to happen. This is usually a manual process and sometimes it can severely impact the query experience of users
ClickHouse Alternatives
ClickHouse has enjoyed tremendous growth in the last decade thanks to its adoption by many large enterprises for its excellent query performance in OLAP scenarios. But ClickHouse is starting to show its age.
Analytics has become more democratized, more complex, and more important to mission-critical business operations. ClickHouse was built to be optimized for the old world of analytics, and now the list of challenges it faces is growing quickly.
It should come as no surprise that newer solutions that have been designed with modern analytics use cases in mind are starting to see an influx of ClickHouse converts. StarRocks is one of those solutions (along with its enterprise-ready version, CelerData). Having debuted less than three years ago, StarRocks has addressed the challenges faced by ClickHouse with a new query engine designed from ground up.
How StarRocks and ClickHouse Are Different
At first glance, StarRocks and ClickHouse appear to have a lot in common. Dig deeper, however, and significant differences start to appear in terms of function, performance, and application scenarios.
StarRocks was designed from the ground up to address the challenges ClickHouse users were facing. First and foremost, StarRocks delivers even faster query performance for the single table queries compared to ClickHouse. Our benchmark results with standard TPC-H data sets show StarRocks is 3x to 5x faster than ClickHouse.
There are other features that make StarRocks much easier to manage than ClickHouse:
- While ClickHouse struggles with joined queries, StarRocks delivers excellent query performance on joined tables
- ClickHouse was not designed for high-concurrency queries, StarRocks can handle up to 100x times more concurrent sessions compared to ClickHouse
- ClickHouse’s support for mutable data are limited, StarRocks is designed for real-time data updates
- ClickHousClickHouse scales via node expansions and redistribution, StarRocks online elastic scaling
Together, these differences result in significant performance differences in these two solutions, with StarRocks outperforming ClickHouse by 300%.
To learn why StarRocks is able to deliver such a significant performance advantage over ClickHouse, check out the latest benchmark report.