


Join StarRocks Community on Slack
Connect on SlackIceberg is a table format for managing large-scale analytical datasets. Its data warehouse-like capabilities allow users to run heterogeneous analytical workloads directly on top of it. However, users often encounter query performance bottlenecks when dealing with Apache Iceberg tables.
Analytical queries are known to be heavy on query execution. However, a large portion of performance bottlenecks are actually caused by slow metadata retrieval. This article explores common challenges and offers a strategy to overcome them, ensuring that your Iceberg queries perform optimally.
Challenges Caused By Slow Iceberg Metadata Retrieval
Slow Apache Iceberg retrieval is a hidden cost that, if overlooked, can cause severe issues to your production system. These issues include:
-
Performance issues with large queries: Queries spanning long periods or large datasets often get stuck during Iceberg job planning. In extreme cases, this can lead to Full Garbage Collection, causing significant disruptions to your service.
-
Sluggish response with small queries: Even smaller queries can suffer from slow metadata retrieval, failing to meet tight latency requirements (e.g., a P90 under 3 seconds).
-
Challenges in metadata-related operations: Beyond query performance, operations using Iceberg metadata can suffer from slow metadata retrieval. For example, query rewrite for materialized view frequently compares query plans between queries, and slow metadata retrieval can heavily affect its performance and stability.
These issues force users to manually optimize their Iceberg metadata by minimizing column stats and rewriting manifests. Although these optimizations alleviate the issues, they do not address the root cause, and often, the issues persist afterward.
Root Causes of Slow Metadata Retrieval in Iceberg
To address these performance issues, it’s crucial to understand the root causes of slow Apache Iceberg metadata retrieval:
-
Metadata decompression overhead: Iceberg stores metadata in manifest files using the highly compressed Avro format. While this saves space, decompressing and parsing these files can be time-consuming. For instance, decompressing an 8MB file can take up to one second, which is unacceptable in scenarios requiring rapid query responses.
-
Many Avro files to decompress and read: Each manifest file may contain references to thousands of data files. Even if a query only needs data from a few of these files, the entire manifest file must be parsed, compounding the problem further.
-
Dependency on master node resources: The metadata retrieval process heavily depends on the CPU and memory resources of the master node (e.g., the FE node in StarRocks or the Coordinator in Trino). As metadata size and query concurrency increase, the master node can become a bottleneck, causing performance issues.
Solutions to Accelerating Iceberg Metadata Retrieval
When metadata becomes large and cumbersome, what can be done to address the resulting performance issues? Here, we will look at how we could address this challenge.
Using the parallel computing capabilities of modern MPP query engines
One of the most effective ways is to utilize the parallel computing capabilities of modern query engines. Query engines can distribute the task of filtering, reading, and decompressing manifest files across multiple nodes. Processing multiple manifest files in parallel can linearly reduce the time required for metadata retrieval, thereby speeding up the job planning phase and making the execution of large queries much more efficient. This is especially useful for larger queries that involve many manifest files.
Caching deserialized Avro files
For smaller queries, where the overhead of repeatedly decompressing and parsing manifest files can cause unnecessary delays, an alternative strategy is to cache deserialized Avro files. By storing these deserialized files in memory, subsequent queries can bypass the decompression and parsing stages entirely, directly accessing the necessary metadata. This caching mechanism can drastically reduce retrieval times, making the system more responsive and capable of meeting tight latency requirements.
The Benefits of Using StarRocks with Iceberg for Metadata Retrieval
While parallel processing and caching are effective strategies, implementing them efficiently requires a query engine that is designed to handle large-scale, complex workloads. StarRocks is one such solution.
What is StarRocks?
StarRocks is an open-source, massively parallel processing (MPP) query engine optimized for data warehouse workloads on data lakes. It is designed to overcome the limitations of traditional query engines by leveraging a distributed architecture that maximizes the parallel processing power of modern hardware.
How StarRocks' architecture works with parallel processing
StarRocks utilizes a unique architecture composed of Frontend (FE) nodes and Compute Nodes (CNs) to distribute workloads and optimize performance:
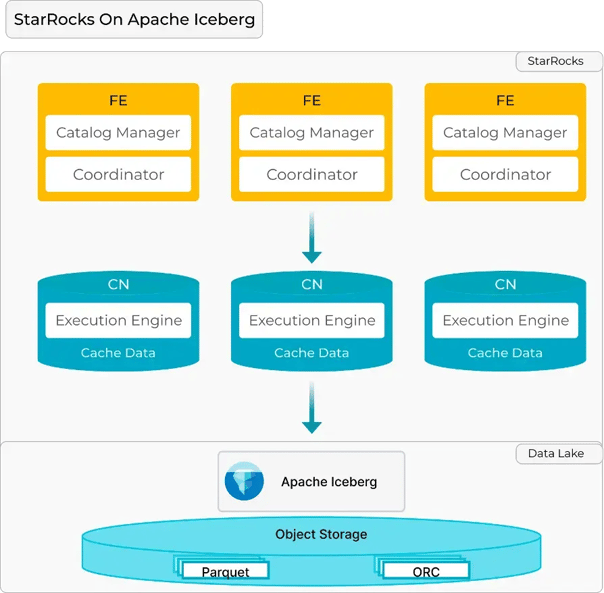
Figure 1: StarRocks architecture example
-
Frontend (FE) Nodes: The FE nodes in StarRocks are responsible for metadata management, performing query planning, and coordinating the overall execution of these queries. However, unlike traditional systems where the coordinator node might become a bottleneck, StarRocks distributes the heavy lifting across multiple CNs.
-
Compute Nodes (CN): The CNs handle the actual data processing tasks. When a query is executed, the FE node generates a distributed execution plan that is then executed across the CNs.
StarRocks’ approach to solving metadata retrieval challenges
StarRocks' 3.3 release addresses the challenges by implementing both the aforementioned solutions and intelligently choosing the one that best suits the query pattern:
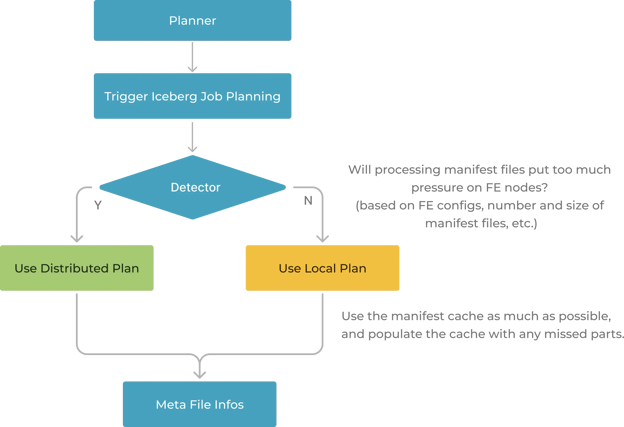
Figure 2: How StarRocks solves metadata retrieval
-
Distributed processing across CNs: For larger queries, StarRocks distributes the job planning and metadata retrieval tasks across its CNs. By parallelizing the processing of manifest files, StarRocks not only speeds up the query planning process but also makes it scalable. StarRocks also integrates a pipeline execution engine within its CNs, enabling tasks to be broken down into smaller, parallelized stages. This allows StarRocks to process different parts of the metadata simultaneously, further improving efficiency.
-
Caching deserialized manifest files: StarRocks introduces a caching mechanism for smaller queries that stores deserialized manifest files. This allows for immediate access to metadata without the need for decompression or parsing, ensuring that small queries are executed swiftly and efficiently.
Apache Iceberg Case Studies With StarRocks: Real-World Applications
Let's see this in action and take a look at a few applications of this approach.
A social media platform handling large queries
A major social media platform once struggled with large ad-hoc queries on data with 300+ columns and a daily increment of over 100 billion rows. This dataset accumulated huge amounts of metadata that often stalled query planning due to slow metadata retrieval on older versions of StarRocks.
After they upgraded to StarRocks 3.3, distributed metadata retrieval enabled them to linearly scale their job planning speed. Below are the test results with 4 CNs:
|
|
V3.2
|
V3.3 (distributed plan)
|
Improvements (v3.2/v3.3)
|
|
One week data
|
60s
|
11s
|
5.45x
|
|
Two weeks data
|
72s
|
14s
|
5.14x
|
Not only does it achieve performance that was previously impossible, but this ability to scale also reduces reliance on manual Iceberg metadata optimization, significantly reducing wasted labor.
A Travel company optimizing small query performance
A leading travel company faced challenges with slow metadata retrieval for their BI reporting use case. Although the total query execution time was not high, job planning took over 50% of the total query time.
After upgrading to StarRocks 3.3, StarRocks’ caching mechanisms for deserialized Avro files sped their average query planning time from 1s to 100ms, a 10x increase in performance.
Better Metadata Retrieval With Iceberg Is Possible
Optimizing metadata retrieval in Apache Iceberg is crucial for maintaining high query performance, especially as data volumes grow. StarRocks, with its distributed architecture and advanced processing capabilities, provides a powerful solution to these problems, ensuring that both large and small queries are executed efficiently without relying solely on manual Iceberg metadata optimizations.
Join the StarRocks community to learn more about how it can help you optimize your data processing needs and overcome the inherent challenges of Apache Iceberg.