


Join StarRocks Community on Slack
Connect on SlackAs the needs of your business grow and change, so too will your database design approach. For many, this inevitably leads to denormalizing tables, but this isn't always the right choice. In this article, we'll delve into the topic of denormalization, the problems it can cause, and its alternatives.
Flat Table vs. Multi-Table Schema
There are many ways to design your table schemas, depending on the nature and complexity of the data, as well as the specific requirements of the application. On a high level, it boils down to two categories:
-
Flat Table Schema (one big flat table): A single, large table that contains all the data.
-
Multi-Table/Relational Schemas: Multiple tables linked together through relationships.
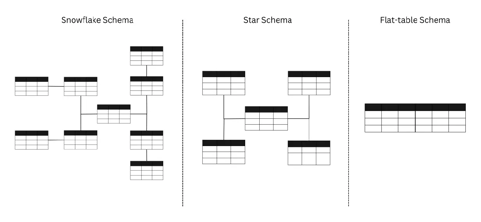
Figure 1: Schema Examples
Normalization: A Pillar of Relational Databases
Normalization is a process of efficiently organizing data in a database, and it's been a fundamental principle in relational database design. There are several advantages to normalization:
-
Reducing Redundant Data: By ensuring data is stored only once, normalization eliminates redundancy. This can save storage space and ensure data integrity, as there is a single source of truth.
-
Simpler Queries: With data stored in a structured manner, querying becomes more straightforward. One doesn't need to navigate through heaps of redundant data to retrieve information.
The Rise of Denormalization and Its Rationale
Despite the obvious benefits of normalization, there has been a trend towards denormalization. But why? The answer lies largely in the demands of modern-day analytics and the challenges posed by the current Online Analytical Processing (OLAP) databases. Many of the OLAP databases, especially in real-time analytics, are not designed to handle JOIN operations at scale. As businesses need to analyze large datasets in real time, JOIN operations easily become a bottleneck.
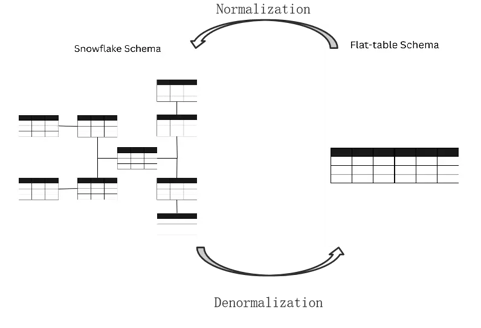
Figure 2: Normalization to Denormalization Cycle
To mitigate these challenges, denormalization is seen as a workaround. By merging tables and reducing the need for JOINs, queries can be sped up. However, this approach is not without its problems.
The Dark Side of Denormalization
While denormalization might seem like a silver bullet to some scaling challenges, it introduces its own set of issues:
-
Rigid Data Pipeline: Denormalization makes the data pipeline less flexible. Any change in the schema might require a complete reconfiguration of the pipeline. If historical data needs to be in line with the new schema, backfilling becomes a cumbersome and often expensive task.
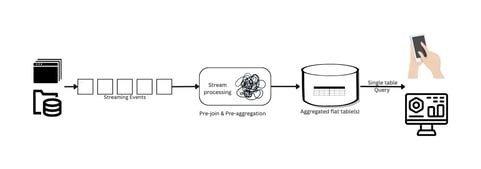
Figure 3: A Complex Data Pipeline
-
Increased Complexity And Cost: In scenarios that require real-time analytics, denormalization necessitates using stream processing tools. This demands not just SQL but actual coding, making the development and maintenance more resource-intensive and costly.
The Solution: On-the-Fly JOINs
Modern-day JOINs offer flexibility without compromising efficiency. Their previous reputation for hampering performance has long been debunked, especially with advancements in OLAP databases that have made them more efficient than ever. Here's what you should consider if you want to avoid denormalization:
Massively parallel computation:
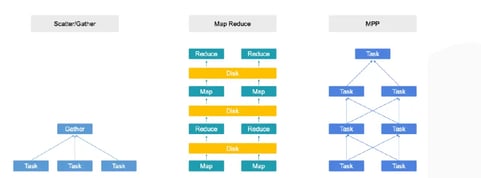
Figure 4: MPP Structure Comparison
Massively parallel processing (MPP) architecture can greatly improve JOIN performance in large tables by dividing a query into multiple computing instances and running them across separate nodes. MPP architectures offers near-linear horizontal scalability, increasing performance proportionately with the addition of computational resources. The key to this scalability is the ability to shuffle between nodes, which is essential for high-cardinality aggregation and large table JOINs.
Cost-based optimization (CBO):
Optimizing a query is like going from one place to another, it does not matter how fast we go, if the route we take is unoptimized, a low latency query becomes impossible. When compared to a rule-based optimizer (RBO), instead of flying blind and relying on predefined rules with little consideration of the data or system status, the CBO utilizes actual data statistics and system status, ensuring the most efficient query route is always selected.
Global runtime filter:
This is pivotal for enhancing JOIN efficiency. It works by dynamically trimming unnecessary data during the query process, reducing the amount of useless data that is being scanned and processed, and hence speeding up intricate multi-table queries.
System-level optimizations:
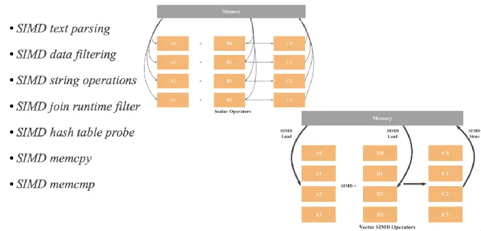
Figure 5: SIMD Optimization
Techniques like Single Instruction and Multiple Data (SIMD) are important for performant OLAP queries, especially for those with JOINs. When combined with columnar storage, SIMD allows data to be processed more efficiently in bigger batches, taking full advantage of modern CPUs' parallel computing capabilities
Partial updates - a "back-up plan" for high-demand scenarios:
-
Even with advanced JOIN techniques, there are situations, like intensive customer-facing analytics, where denormalization might still be necessary. Here, partial updates serve as a savior.
-
They facilitate updates to specific row columns, bypassing the need for joining multiple tables in upstream tasks. This approach provides a nimble, effective method for handling intricate data challenges.
JOINs vs. Denormalization: Make the Right Choice
While normalization stands as a foundational pillar of relational databases, the unsatisfactory JOIN performance of today's OLAP databases has led to a rise in denormalization. This approach, although advantageous in certain scenarios, introduces its own complexities and costs. Thankfully, with technological advancements, the once-feared on-the-fly JOIN operation has re-emerged as robust alternative, mitigating the need for extensive denormalization.
If you want to experience the benefits of on-the-fly JOINs firsthand, check out Celerdata Cloud. Built on top of the open-source engine, StarRocks, Celerdata Cloud addresses the denormalization problem head-on with its ability to perform low latency JOIN queries at scale. Sign up at cloud.celerdata.com for a free trial.