


Questions About Materialized Views?
Connect on SlackWhat is a Materialized View?
A materialized view is essentially a snapshot of the results of a query stored in a database. It can be a local copy of data from a remote source, a filtered version showing only specific rows or columns, or even a summary that uses an aggregate function. The concept of materialized views is rooted in two key ideas: materialization and views.
Materialization refers to the process of storing intermediate query results, which speeds up future computations by reusing precomputed data. Think of it as caching information to save processing time.
Views, on the other hand, focus on simplifying the user experience. They create a logical layer that presents data in a unified, easy-to-understand format, hiding the complexity behind the scenes and making permission management more straightforward.
Imagine you're running an online store with a huge database containing millions of sales records. You frequently need to check total sales for each product category. Instead of running a complex query every time, you can set up a materialized view to calculate these totals in advance. When you need the data, the system quickly retrieves it from the pre-aggregated results, saving both time and computational resources.
Here are some key concepts:
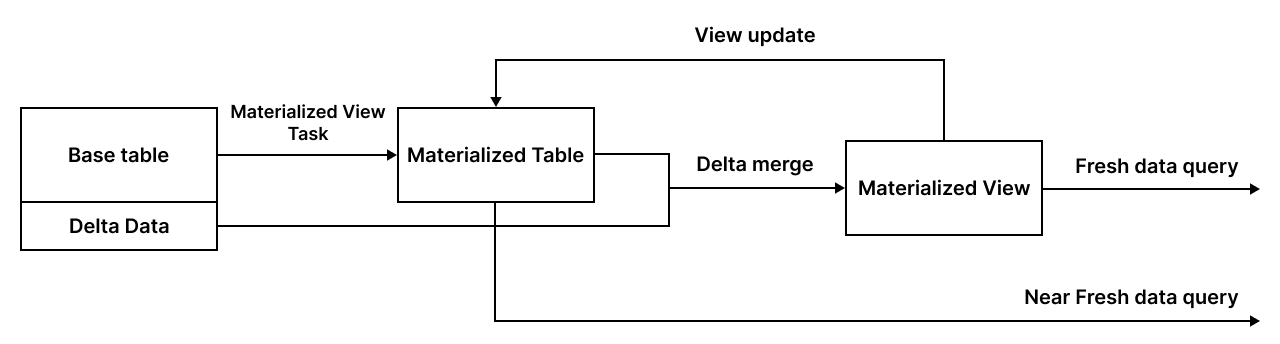
- Base Table: The original table from which the materialized view is created (e.g., your full sales data).
- Materialized Table: A new table that holds the precomputed results, such as the total sales per product category.
- Materialized View: The user-facing view that presents these precomputed results, often including both static data and incremental updates.
- Materialized View Task: The process that updates the materialized view by transforming data from the base table into the materialized table.
This process ensures faster queries and more efficient data handling.
Understanding Core Functionalities of Materialized Views
Materialized views are essential for boosting data processing and improving query performance. Let’s break down their key functionalities:
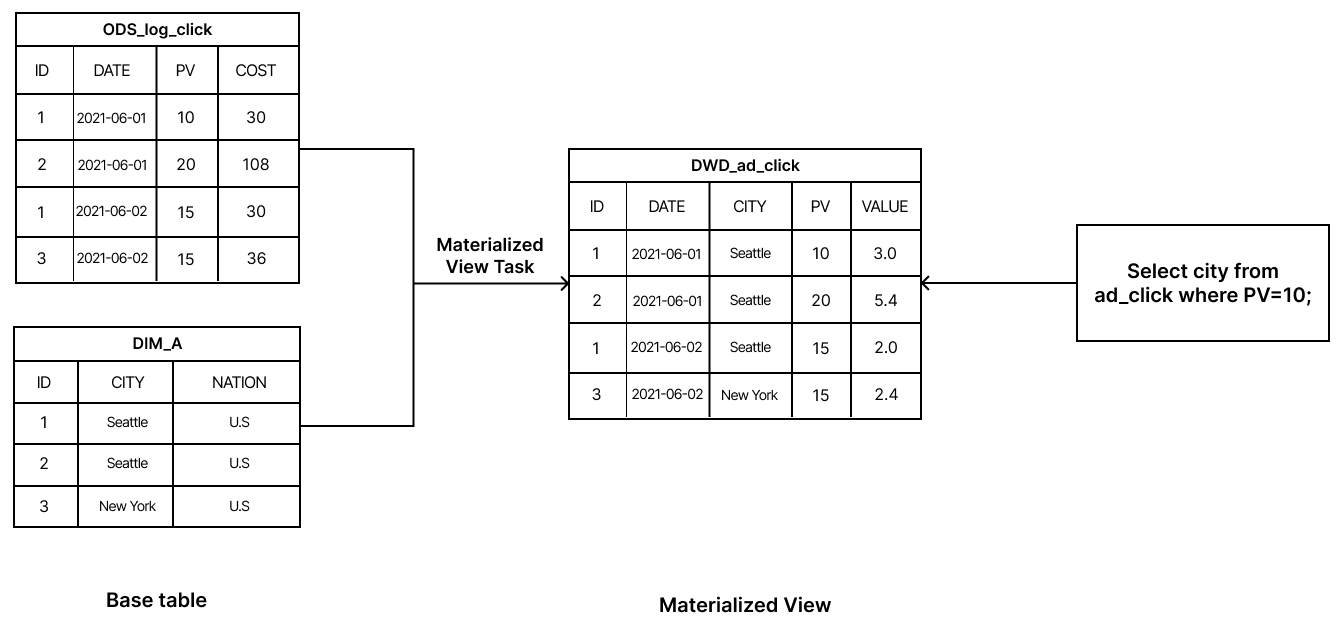
- Materialization: This is the process where materialized views store the results of a query as physical tables in the database. These tables are just like regular tables, but they contain precomputed data, meaning the system doesn’t have to recalculate everything from scratch when retrieving information. The data is taken from the base table and stored in a new, easily accessible format, referred to as a "materialized table."
-
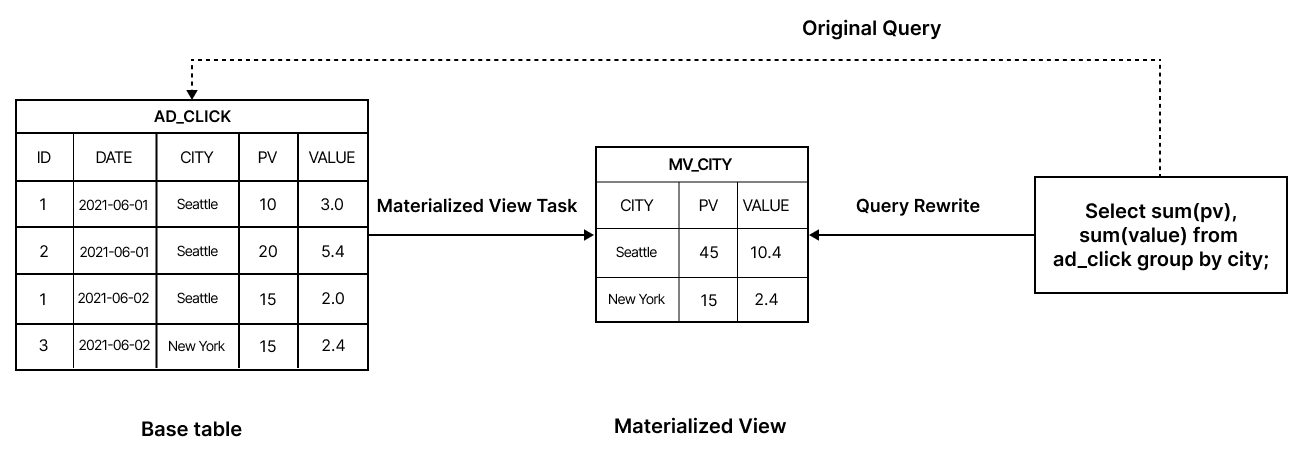
Partitioning: Partitioning a materialized view—say, by day—gives you more control over how and when data gets refreshed or maintained. You can align partitions with external table sources (like Hive or Iceberg), allowing the materialized view to automatically update as new data comes in. This makes managing large datasets much easier and more efficient.
-
Refresh Mechanisms: Materialized views offer various ways to keep data up to date. You can set them to refresh automatically when new data is imported, schedule refreshes (e.g., every hour), manually trigger updates, or opt for incremental refreshes. This flexibility ensures that your data stays fresh based on your specific business needs.
-
Resource Group for Isolation: One challenge in managing databases is ensuring that maintenance tasks don’t interfere with regular user queries. Materialized views handle this by using resource groups to keep the system's query load separate from maintenance operations. This means your system can handle different tasks at the same time without slowing down the front-end performance.
-
Advanced Query Support: Materialized views aren’t just for simple queries—they can also handle more complex operations like joins and aggregations. Whether your data comes from traditional databases like MySQL or PostgreSQL, or modern data lakes like Hive or Iceberg, materialized views allow you to run these complex queries faster by working with precomputed results, reducing the strain on your system.
In summary, materialized views make querying much more efficient by precomputing data based on your chosen refresh schedules. They also allow the system’s query optimizer to automatically rewrite SQL queries to use these precomputed results, significantly reducing computational load. This flexibility gives users a smart way to balance performance, cost, and timeliness without needing to change their SQL code manually.
What Problems Do Materialized Views Solve?
Materialized views bring together several key features that solve two major challenges in data engineering: data processing complexity and resource management.
Simplifying Data Processing
Materialized views simplify the complexity of data engineering tasks. They use a clear and easy-to-understand syntax to model data processes, which means users don’t have to worry about the technical details of how the data is computed. This reduces the effort required for data processing and makes the overall workflow more manageable.
Streamlining Data Flow with Refresh Mechanisms
Managing how data flows between different systems can be tricky, but materialized views help by automating this. Their refresh mechanism ensures that data remains up to date without the need for manual intervention, making it easier to manage dependencies and maintain data quality across systems.
Efficient Resource Management
Materialized views address the issue of resource isolation through Resource Groups. This technology ensures that different tasks, like front-end queries and background processing, don’t interfere with each other. By separating workloads, materialized views help allocate resources more efficiently and prevent simple queries from consuming unnecessary computing power.
Flexible Data Modeling and Performance Boost
One of the biggest advantages of materialized views is their ability to accelerate queries without requiring businesses to constantly modify their data models. They allow companies to adapt to changing data needs and optimize performance automatically, all while keeping the data structure flexible and easy to manage.
Balancing Performance, Timeliness, and Cost
Materialized views help organizations strike the right balance between performance, timeliness, and cost. By offering different refresh modes, companies can tailor their data management strategies to their specific needs. This ensures that data is always accessible, without overspending on computational resources.
How to Use Materialized Views in StarRocks
Materialized views (MVs) in StarRocks are designed to make data pipelines simpler, reduce query delays, and automate performance improvements. Over time, MVs have become essential for handling big data, allowing businesses to run fast queries on large datasets without the need to recalculate results every time. Instead of manually managing complex pipelines for transforming and aggregating data, MVs let you query data lakes directly and create performance layers on demand. This approach cuts down on waiting times and allows for seamless data access without requiring changes to your queries or front-end processes.
MVs also automatically optimize queries, recommending performance improvements based on specific workloads. This is especially useful for businesses where data pipelines frequently change due to new data sources or schema updates.
Understanding Materialized Views in StarRocks
Storage for Materialized Views
Materialized views are stored as regular tables in StarRocks, inheriting key features like sorting, distribution, and indexing from standard tables. This allows MVs to benefit from existing storage optimizations. When creating an MV, familiar options like DISTRIBUTION BY and ORDER BY give you control over how the data is stored and accessed. A key advantage is the ability to create indexes on MVs, letting users tweak query performance based on their needs. Once an MV is created, its properties can be updated to adapt to changing requirements.
SQL Queries for MVs
StarRocks supports a wide range of SQL queries for materialized views, including SELECT statements, common table expressions (CTE), and UNION operations. MVs can work with both internal and external tables, supporting formats like Hive, Hudi, Iceberg, and Delta Lake. For the best compatibility, it's recommended to use StarRocks version 3.2 or later.
Keeping MVs Up to Date with Refresh Tasks
To ensure materialized views stay synced with their source tables, regular refresh tasks are necessary. These tasks, defined in SQL, manage the synchronization process to keep the MV data current. Users can set execution parameters such as resource groups and warehouses to ensure maintenance tasks don’t impact business intelligence (BI) queries. StarRocks also offers diagnostic tools and system tables like information_schema.tasks_run to monitor and optimize these refresh tasks.
Partitioning in Materialized Views
Effective partitioning is crucial when working with large datasets. When creating an MV, you can use the PARTITION BY clause to specify how data should be partitioned, often based on a column from the source table. Aligning MV partitions with source table partitions allows for partition-level refreshes, ensuring that only changed data is updated.
StarRocks provides several partitioning strategies:
- One-to-One Mapping: Directly maps partitions from the source table to the MV.
- End-to-End Mapping: Aggregates smaller partitions from the source table into larger partitions in the MV, such as rolling up daily partitions into monthly ones.
Changes in fact tables typically only require refreshing the affected partitions in the MV. However, changes in dimension tables may necessitate refreshing the entire MV, so careful partitioning is essential to avoid unnecessary overhead.
StarRocks also offers properties to control refresh behavior, such as how long partitions are retained (Partitioning TTL), how many partitions are refreshed (Partitioning Refresh Number), and how many partitions are automatically refreshed (Auto Refresh Partition Limit).
Handling Schema Changes
Dynamic environments often experience schema changes in source tables, which can affect materialized views. StarRocks tracks these changes and deactivates MVs if there are incompatible updates (e.g., renaming a table triggers an automatic update, while dropping a column may require manual intervention). StarRocks provides commands like AUTO_MV_ACTIVE to reactivate views and ensures that MVs stay synchronized with their source tables.
If you need to change the query logic of an MV, the SWAP WITH command allows for the automatic swapping of two MVs without having to rewrite the query.
Monitoring and Managing MVs
Monitoring the performance and reliability of materialized views is crucial. StarRocks provides several tools to help:
- Query Profile: Analyzes query performance and explains why certain queries didn’t use the MV.
- Monitoring Templates: Track key metrics like failed jobs and running tasks.
- Auditor Log: Tracks which MVs were used in queries and identifies areas for optimization.
- System Tables: Tables like
sys.object_dependenciesdisplay the relationships between source tables and MVs, whiletask_runsshows the execution history of MV-related tasks.
With these tools, StarRocks ensures materialized views perform optimally, making data management more efficient and effective.
Auto-Rewrite Query to Materialized Views
.png?width=704&height=307&name=StarRocks%20Rewrite%20Improvements%20(1).png)
One of StarRocks' standout features is its auto-rewrite capability, which allows the system to automatically adjust queries to take advantage of materialized views (MVs). This is especially useful for business intelligence (BI) workloads that often rely on complex queries. With auto-rewrite, the system uses pre-aggregated data, pre-joined tables, and optimized projections to speed up queries without manual intervention.
Here are a few types of query rewrites:
- Slice Rewrite: This pre-aggregates data based on specific filters or dimensions, making lookups much faster.
- Roll-Up Aggregation: Instead of scanning all raw data, this approach aggregates results from the MV itself, saving time and resources.
Real-World Use Cases for StarRocks' Materialized Views
Airbnb Minerva Metric Platform
Airbnb’s Minerva is an internal metrics platform that started by merging dimension and fact tables into wide tables. In its initial version (V1), these wide tables were stored in Druid, while Presto was used to query Hive tables. This setup handled 30,000 metrics and 4,000 dimensions, supporting A/B testing and a variety of data use cases. However, this approach came with some downsides:
- It didn’t respond well to data changes.
- Updating dimensions required significant reprocessing.
- It was costly in terms of data processing.
With StarRocks 3.0 and 3.1, Minerva saw major improvements. The materialized view rewrite capabilities allowed for more complex queries like View Delta Join and Query Delta Join. This led to:
- Fewer MVs but with support for more query types, including aggregation and union operations.
- Efficient handling of complex queries that previously required multiple joins with a single MV.
Optimizing with View Modeling and Pruning
Airbnb also utilized view-based data modeling combined with materialized views, generated columns, and view pruning. In scenarios like risk control, wide views are pruned dynamically to remove unnecessary data structures. This pruning helps optimize query performance, ensuring that only relevant tables are included in queries.
Key benefits of this approach include:
- Optimized Query Performance: Pruning irrelevant data improves efficiency, speeding up execution.
- Derived Metrics: New columns can be easily created from existing data using simple calculations.
- Simplified Data Management: Generated columns allow new metrics to be added without restructuring entire tables.
- Improved Data Performance: MVs selectively boost specific query performance where needed.
- Automatic View Rewriting: StarRocks versions 3.2 and 3.3 introduced automatic rewriting of logical views into MVs, offering seamless performance improvements without manual adjustments.
Real-Time Dashboard at DiDi
DiDi, China’s leading ride-hailing company, needed a real-time dashboard to handle billions of records daily with minimal query latency. Using both synchronous and asynchronous MVs, DiDi was able to aggregate data in real-time and refresh every 30 seconds to ensure accuracy, reducing manual intervention and supporting high concurrency.
Gaming Dashboard Optimization
Tencent Games, one of the largest gaming companies in the world, faced slow dashboard performance, with response times between 10 seconds and 2 minutes. After switching to StarRocks and implementing MVs, dashboard latency dropped to under two seconds, significantly improving performance and user experience.
Trip.com’s BI Platform
Trip.com struggled with slow query performance on their BI platform due to complex joins and aggregations. By migrating to StarRocks and using nested MVs, they improved query performance by 5-10x, reducing storage costs and optimizing their system.
Financial Institution Metrics Layer
A financial institution transitioned from a resource-heavy cube system to materialized views. This change significantly lowered costs, enhanced query performance, and reduced the storage overhead required to manage metrics.


