


Join StarRocks Community on Slack
Connect on SlackIn the big data era, data is one of the most valuable assets for enterprises. The ultimate goal of data analytics is to power swift, agile business decision making. As database technologies advance at a breathtaking pace in recent years, a large number of excellent database systems have emerged. Some of them are impressive in wide-table queries but do not work well in complex queries. Some support flexible multi-table queries but are held back by slow query speed.
Each type of data has a data model that best represents them. However, in real business scenarios, there is no such thing as ultra-fast data analytics under the perfect data model. Big data engineers sometimes have to make compromises on data models. Such compromises may cause long latency in complex queries or damage the real-time query performance because engineers must take the trouble to convert complex data models into flat tables.
New business requirements put forward new challenges for database systems. A good OLAP database system must be able to deliver excellent performance in both wide-table and multi-table scenarios. This system must also reduce the workload of big data engineers and enable customers to query data of any dimension in real time without worrying about data construction.
Query Latency Equally Important in Wide-table and Multi-table Scenarios
StarRocks is committed to delivering blazing-fast query experience for all analytics scenarios. It is positioned to maximize data value under the most appropriate model and make data analytics more simple and agile for enterprises. In the benchmark, we use standard datasets to compare the wide-table and multi-table query performance of StarRocks with well-known database systems in the industry, including ClickHouse, Apache Druid®, and Trino. If you have any suggestions on the benchmark (such as test configurations or optimizations), please feel free to let us know.
Wide-table Testing Using SSB
Star schema benchmark (SSB) is designed to test basic performance metrics of various OLAP database products. SSB uses a star schema test set [1] that is widely applied in academia and industry.
ClickHouse flattens the star schema into a wide flat table and rewrites the SSB into a flat table benchmark [2]. Therefore, in flat-table scenarios, we use the table creation method in ClickHouse to conduct a PK test on StarRocks, ClickHouse, and Apache Druid.
In addition, we conduct further performance testing on the aggregation of low-cardinality fields.
Multi-table Testing Using TPC-H
TPC-H is a decision support benchmark developed by the Transaction Processing Performance Council (TPC). TPC-H can be used to build models based on real production environments to simulate the data warehouse of a sales system. The main performance metrics are the response time of each query. The TPC-H benchmark evaluates a database system against the following capabilities:
- Examine large volumes of data.
- Execute queries with a high degree of complexity.
- Give answers to critical business questions. [3]
ClickHouse and Apache Druid cannot finish the TPC-H test set. Therefore, in multi-table scenarios, we perform a PK test between StarRocks and Trino.
Benchmark Results
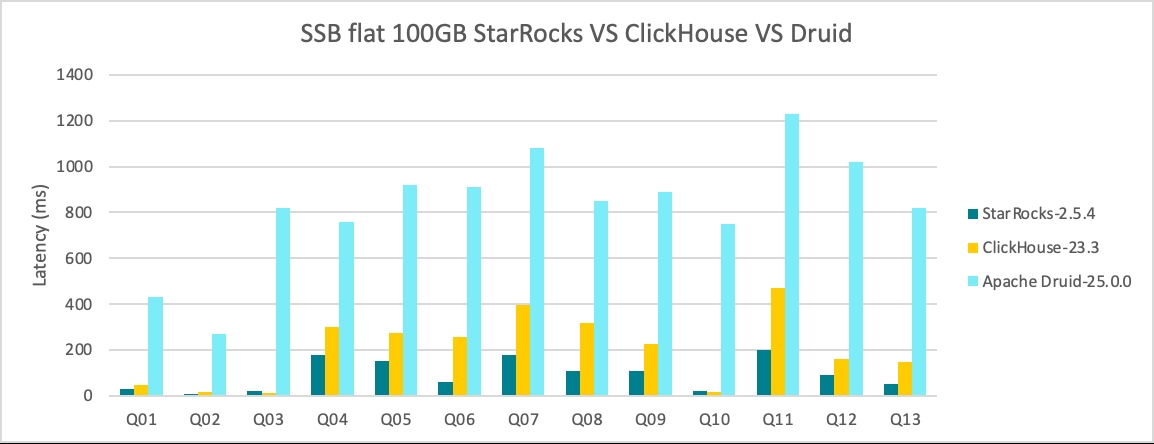
StarRocks Offers 2.2x Performance over ClickHouse and 8.9x Performance over Apache Druid® in Wide-table Scenarios Out of the Box
Among the 13 queries performed on the SSB flat tables, ClickHouse has a response time 2.2x that of StarRocks, and Apache Druid 8.9x that of StarRocks.
StarRocks performs even better when the bitmap indexing and cache features are enabled, especially on Q2.2, Q2.3, and Q3.3. The overall performance is 2.2x that of ClickHouse and 2.9x that of Apache Druid.
StarRocks Offers 4.05x Performance over Apache Druid® in Wide-table Scenarios with Bitmap index
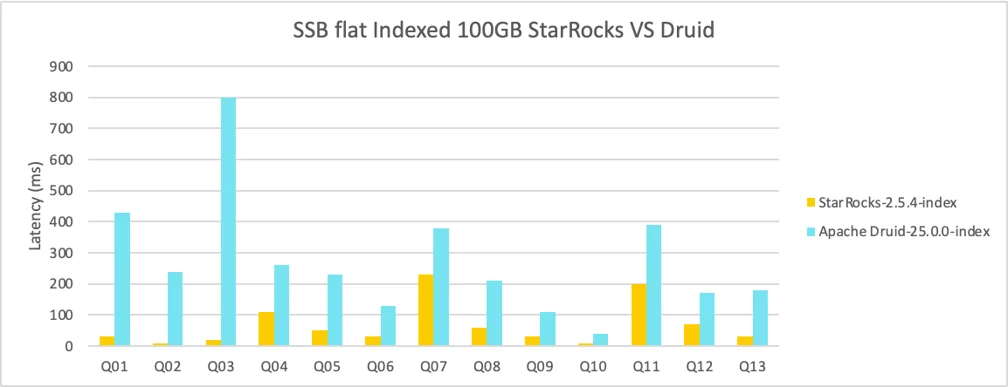
StarRocks also performs well when the bitmap indexing is enabled. The overall performance is 4.05x that of Apache Druid.
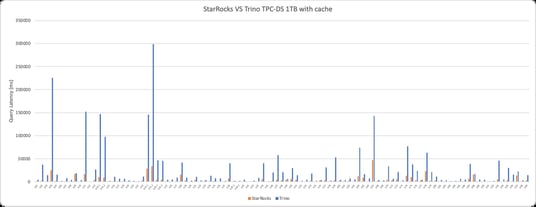
StarRocks Delivers 5.54x Query Performance Than Trino in Multi-table Scenarios
We perform a test on 99 queries against a TPC-H 100 GB dataset. StarRocks native storage and StarRocks external tables for Apache Hive™ are used for queries. We use StarRocks Hive external tables and Trino to query the same copy of data that is stored in the ORC format and compressed in the ZLIB format.
Trino's overall query response time is 5.54x that of StarRocks.
Why Is StarRocks So Fast?
StarRocks is committed to delivering superior query performance for customers. StarRocks has a simple architecture, a vectorized execution engine, and a newly designed cost-based optimizer (CBO). All these features enable real-time data analytics and efficient queries on real-time updated data. Customers can use StarRocks to build various models including wide tables, star schema, and snowflake schema. In addition, StarRocks allows access to data that is stored in Hive, MySQL, and ElasticSearch by using external tables, further accelerating queries.
Vectorized Execution Engine
The vectorized execution engine makes more efficient use of CPUs because this engine organizes and processes data in a columnar manner. Specifically, StarRocks stores data, organizes data in memory, and computes SQL operators all in a columnar manner. Columnar organization makes full use of CPU cache. Columnar computing reduces the number of virtual function calls and branch judgments, resulting in more sufficient CPU instruction flows.
The vectorized execution engine makes full use of SIMD instructions. This engine can complete more data operations with fewer instructions. Tests against standard datasets show that this engine enhances the overall performance of operators by 3 to 10 times.
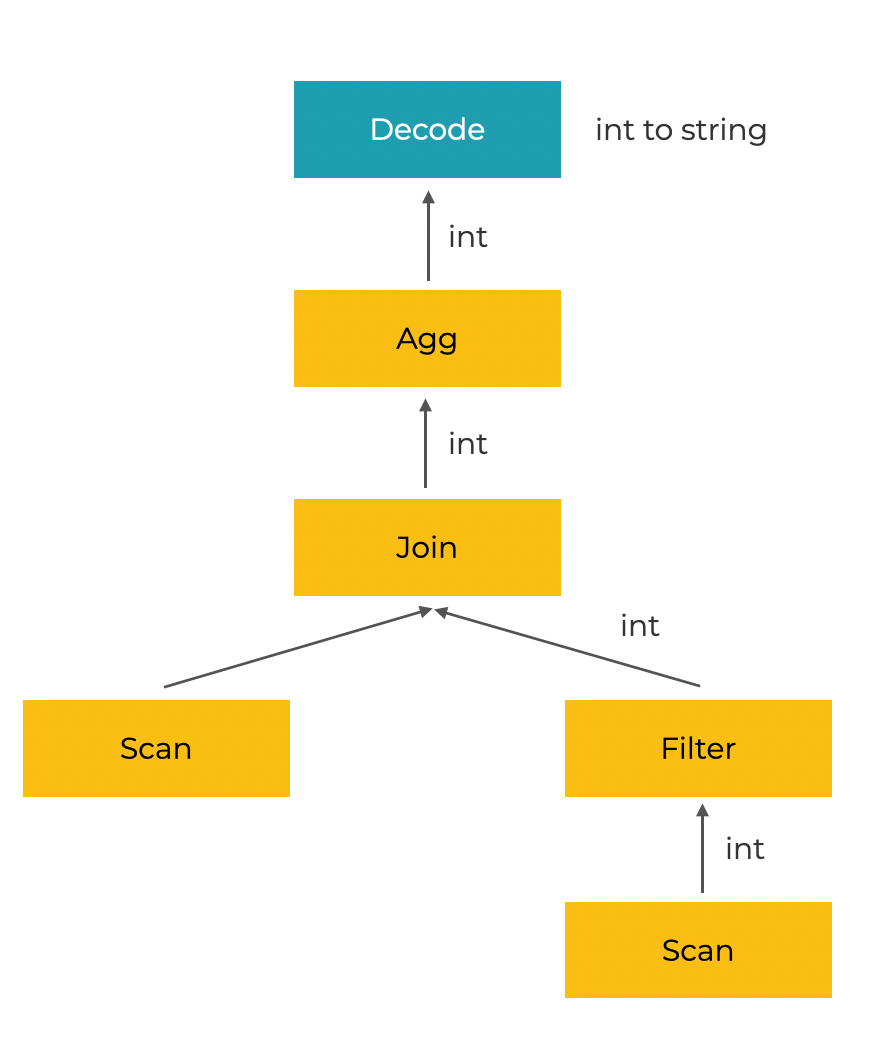
In addition to vectorization, StarRocks has implemented other optimizations for the query engine. For example, StarRocks uses the Operation on Encoded Data technology to directly execute operators on encoded strings, without the need for decoding. This noticeably reduces SQL complexity and increases the query speed by more than 2 times.
Cost-based Optimizer
Performance of multi-table join queries is difficult to optimize. Execution engines alone cannot deliver superior performance because the complexity of execution plans may vary by several orders of magnitude in multi-table join query scenarios. The more the associated tables, the more the execution plans, which makes it NP-hard to choose an optimal plan. Only a query optimizer excellent enough can choose a relatively optimal query plan for efficient multi-table analytics.
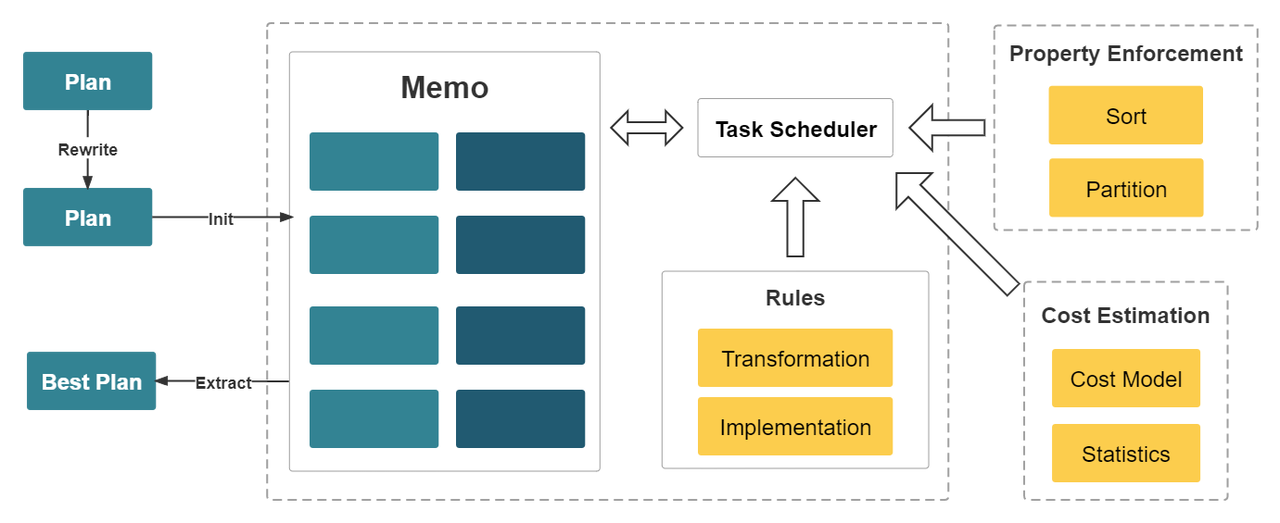
StarRocks designs a brand-new CBO from scratch. This CBO is cascades-like and is deeply customized for the vectorized execution engine with a number of optimizations and innovations. These optimizations include the reuse of common table expressions (CTEs), rewriting of subqueries, Lateral Join, Join Reorder, strategy selection for distributed Join execution, and low-cardinality optimization. The CBO supports a total of 99 TPC-DS SQL statements.
Moreover, continuously optimized HashJoin operators, together with the CBO enables StarRocks to deliver better multi-table join query performance than competitors, especially in complex multi-table join queries.
Bitmap Indexing
Indexing is the most common method for accelerating wide-table queries. StarRocks uses sorting to create primary indexes and uses MinMax and zone maps for fast filtering. It also supports bitmap-based secondary indexes. Bitmap indexing provides good filtering for equivalent, non-equivalent, and range queries on suffix columns.
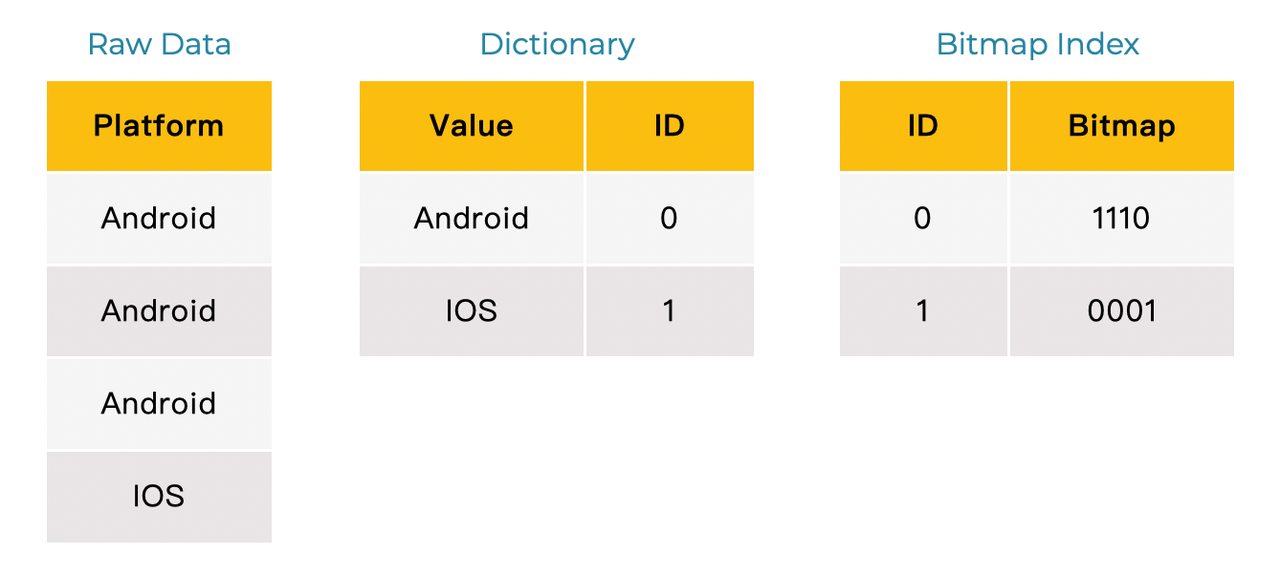
Global Dictionary for Low-Cardinality Fields
Low-cardinality string fields are frequently used in OLAP systems. Compared with string fields, int fields are more friendly to the cache, computing, and memory due to their fixed length. StarRocks 2.0 constructs a global dictionary for low-cardinality fields to convert string fields into int fields. In addition, StarRocks 2.0 has optimized the dictionaries for coding, expression computing, and operator computation to greatly improve the performance of count distinct and group by. Users do not need to re-load data or specify data types when they create tables. Instead, StarRocks automatically builds dictionaries for low-cardinality fields once the previous query is completed. The query acceleration is transparent to users.
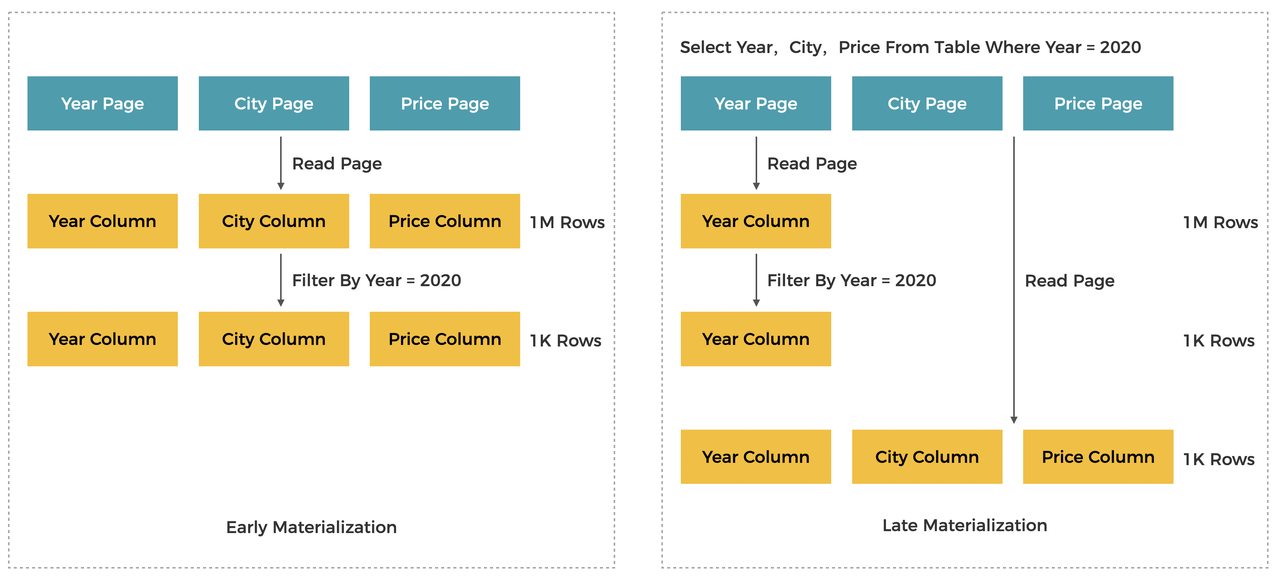
Late Materialization
A wide table has a large number of columns. Late materialization reduces the amount of data scanned by delaying data reading, thereby improving query performance. The following figure shows an example of late materialization. Different from early materialization, late materialization first loads the Year column and performs preliminary filtering on this column to obtain the matched rows. The row numbers are then used to obtain City and Price data. This significantly reduces the number of rows scanned.
StarRocks as a LakeHouse
StarRocks can work as the query engine for a data lake. It uses external tables to query native data stored in Hive. StarRocks can also function as a data warehouse. Users can import data to StarRocks for query acceleration.
When users import data to StarRocks, they can use a variety of powerful features offered by StarRocks, such as partitioning, bucketing, sorting, indexing, and colocated groups. Partitioning and bucketing can prune data to reduce the amount of data scanned, sorting can improve data locality, prefix indexes can speed up queries, secondary indexes can accelerate equivalent and range queries on non-prefix columns, colocated groups can greatly reduce shuffle operations, Local Joins can speed up large table association.
Summary
StarRocks aspires to make data analytics more simple and agile for enterprises. Imagine a database system where you can enjoy superior multi-table and wide-table query performance without the need to perform complex data preprocessing or bear the long latency caused by complex queries. StarRocks makes all this a reality.
Data-driven economy should not be hindered by data model selection. StarRocks' excellent performance in complex queries and wide-table queries makes it possible for enterprises to break the confinement of data models. It helps customers unlock more insights from data under the most appropriate model.
StarRocks has broad use cases in scenarios such as self-service BI, real-time data warehousing, and user-facing analytics. It has been widely deployed and recognized by leading enterprises such as Lenovo and SF Technology. For more use cases, see StarRocks user stories.
[1] Pat O'Neil, Betty O'Neil, Xuedong Chen: Star Schema Benchmark. https://www.cs.umb.edu/~poneil/StarSchemaB.PDF
[2] Star Schema Benchmark in ClickHouse documentation. https://clickhouse.com/docs/en/getting-started/example-datasets/star-schema/
[3] TPC Benchmark H Standard Specification Revision 3.0.0. http://tpc.org/tpc_documents_current_versions/pdf/tpc-h_v3.0.0.pdf
Apache®, Apache Hive™, Apache Druid®, and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.