


Join StarRocks Community on Slack
Connect on SlackTrino has long been praised for its data lake analytics performance, but it now struggles to keep up with modern demands for lower latency and high concurrency at scale. This has many data engineers moving data from lakes to warehouses to speed up queries—a complex, costly ingestion pipeline that undermines data freshness.
These challenges have now been solved, and a new generation of “pipeline-free” query engines promises to deliver low latency, high concurrency queries directly on the data lake.
In this article, we'll dive into the latest developments in data lakehouse querying and discover why it's time to transition from Trino.
The Status-Quo of Data Lake Analytics
In recent years, the concept of a data lake has evolved significantly. Traditionally, data lakes have been cost-effective storage solutions, typically on cloud object storage or HDFS, where various types of data are stored indiscriminately.

The Evolution of Data Lakes
However, developments in data lake technology, especially with the advent of open lake table formats like Apache Hudi, Apache Iceberg, and Delta Lake, have transformed them. These innovations imbue data lakes with data warehouse-like features, including transaction support, schema evolution, compaction, time travel, and DDL support. This integration of features has led to the emergence of "data lakehouses," a hybrid that combines the cost-effectiveness and scalability of data lakes with the functionality of data warehouses.

Data Lakehouse: Data Lake + Data Warehouse
Despite these advancements, there are still challenges. Users continue to transfer data out of data lakes for faster query processing. This migration is necessitated by the lack of performance efficiency in existing data lake query engines, particularly for modern, high-concurrency, low-latency workloads.

Data Lakes: The Reality
This inefficiency often forces users to rely on high-performance data warehouses for query acceleration. While this approach speeds up queries, it introduces additional complexities and costs. These include the overhead of maintaining a data warehouse, data ingestion pipelines, converting data into proprietary formats, and potential data freshness lag. Additionally, it poses integration challenges, such as schema and SQL compatibility, and complicates data governance by diverging from a single source of truth in the data lake.

The True Cost of Data Lake Work
In summary, while data lakehouses represent a significant step forward, integrating high-performance query processing without the need for data migration has been an ongoing challenge across the field.
Unique Challenges With Data Lake Queries

Major Data Lake Analytics Challenges
Optimizing queries in a data lake environments presents unique challenges compared to traditional data warehouse queries. Unlike data warehouses, where CPU optimization is a primary concern, data lake analytics faces obstacles related to data retrieval and management. This difference fundamentally changes the approach to query optimization in data lakes.
Key Challenges in data lake query optimization include:
-
Performance Bottlenecks From Storage: Data lakes, particularly those on the cloud using object storage, offer high throughput but suffer from responsiveness issues. While large files can be transferred quickly, the latency of cloud object storage is significantly higher than local disk storage, often ranging from tens to hundreds of milliseconds.
-
Data File Optimization: In a data lake, data files are often not optimized for query performance. Issues such as a lack of compaction and the presence of numerous small files can adversely affect query efficiency.
-
Control Over Data Distribution: Many data lake table formats lack features like bucketing, which can prune, sort, and manage data effectively for queries. The absence of these features leads to less control over data distribution, impacting query performance.
Why Trino’s Performance Is Falling Behind
Trino, originally a fork of the Presto project, is an open-source distributed SQL engine known for its connectivity to different data sources. Written in Java, Trino marked a significant advancement in data lake technologies with its introduction. Its MPP (Massively Parallel Processing) architecture, which supports in-memory data shuffling, distinguishes it from traditional map-reduce frameworks.

An Overview of Trino
Map-reduce, a process necessary for JOINs and high cardinality aggregations, is often criticized for its slow performance. This is because intermediate results are written to disk for stability, making it unsuitable for low-latency queries. In contrast, Trino's in-memory shuffling is tailored for low-latency querying, greatly reducing query times from hours to minutes even on massive datasets.
Despite its advancements, Trino's performance has started to lag, especially under the intense workloads common in data warehouses that demand low latency and high concurrency.

Introducing StarRocks
In comparison, StarRocks, a newer generation query engine (also MPP but written in C++ with SIMD optimization), excels at performing sub-second queries at scale while handling high concurrency, making it well-suited for demanding data warehouse workloads on data lakes.
Benchmark Numbers: Trino vs. StarRocks
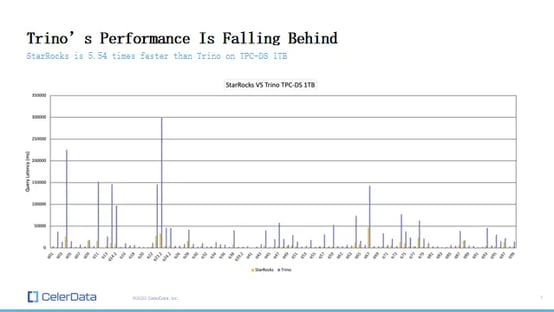
Benchmark Performance: Trino vs. StarRocks
In a benchmark test using TPC-DS with one terabyte of data, StarRocks demonstrated a performance approximately 5.54 times faster than Trino. This test, conducted on the same data stored on S3 and managed by Iceberg, reflects a complex query scenario involving numerous joins and high cardinality aggregations.
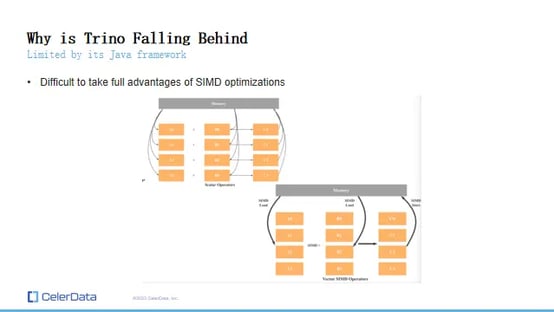
SIMD Issues With Trino
The primary reason for this performance gap lies in Trino's Java-based framework, which struggles with SIMD (Single Instruction, Multiple Data) optimizations. SIMD allows for processing multiple data values with one memory seek, significantly reducing memory seek operations and improving performance.
Trino's current setup in Java limits its ability to fully utilize SIMD, impacting its efficiency, especially compared to applications written entirely in C++. While Trino has moved to Java 21, which will provide some SIMD instruction sets, the extent of SIMD optimization achievable in Java is still limited compared to a complete C++ implementation.

Trino's Limitations
Additionally, Trino faces unique challenges in data lake queries. Scanning and fetching data from external storage can become a significant bottleneck. Trino currently lacks a mature built-in caching framework, often necessitating the use of external frameworks like Alluxio for caching. However, this introduces additional complexities, including maintenance challenges, potential network overhead, and integration difficulties.
StarRocks as an Alternative
StarRocks represents the new generation of query engines, distinguished by its simplicity and performance efficiency. It operates on a straightforward architecture with two primary process types: the Frontend (FE) and Backend (BE), or the compute nodes.
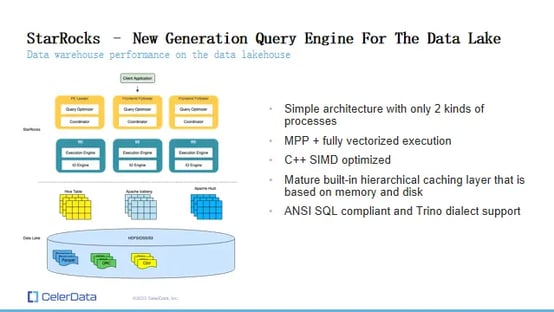
StarRocks Query Engine
Key Features of StarRocks include:
-
MPP Architecture and In-Memory Data Shuffling: Similar to Trino, StarRocks features a Massively Parallel Processing (MPP) architecture with in-memory data shuffling. This setup enables efficient data processing and quick execution of complex queries.
-
Fully Vectorized Execution Engine: StarRocks features a fully vectorized execution framework, enhancing its query processing capabilities.
-
C++ Based Execution Layer: A significant difference from Trino is that StarRocks' execution layer (BE) is entirely written in C++. This allows StarRocks to effectively leverage SIMD (Single Instruction, Multiple Data) optimizations, leading to substantial performance improvements.
-
Built-In Hierarchical Caching Layer: Unlike Trino, StarRocks includes a built-in hierarchical caching layer based on both memory and disk. This feature significantly enhances query performance, especially for repeated queries and data-intensive operations.
-
ANSI SQL Compliance and Trino Dialect Support: StarRocks is ANSI SQL compliant and also supports Trino dialects. This compatibility allows for easy testing and migration for users currently using Trino. Users can deploy a StarRocks cluster and connect to their data lake without needing to change their SQL queries.
While StarRocks is known for its raw performance, its real differentiation lies in features that extend beyond just raw speed. This is particularly relevant in the context of data lakes, where optimization has its limits.
Seamless Query Acceleration With StarRocks Materialized View
A materialized view is essentially the stored result of a SQL query, acting as a form of pre-computation. In StarRocks, creating a materialized view of external data lake data results in the data being written in StarRocks' own format. This process leverages the StarRocks storage engine for query acceleration.
-
Advantages: The materialized view feature in StarRocks allows for co-located joins, indexing, low cardinality optimizations, and bucketing, which are not fully available in data lakes.
-
Query Rewrite Support: StarRocks' materialized views support query rewrites. This means during querying, there is no need to alter SQL scripts; StarRocks automatically routes to the most suitable materialized view for acceleration. This ensures seamless integration and ease of use.
-
Support for Complex Queries: StarRocks' materialized views can handle both single-table and multi-table queries, enabling denormalization and pre-aggregation pre-computations.
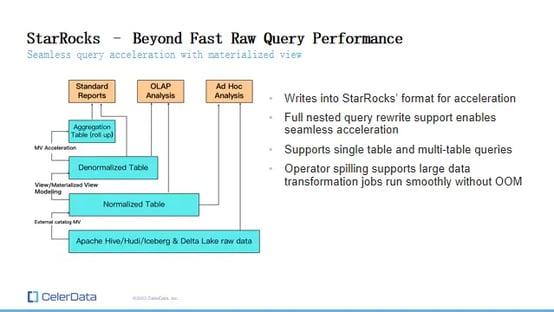
StarRocks Query Performance
StarRocks, similar to Trino, features in-memory data processing for low-latency queries. A standout feature is its operator-spilling capability:
-
Handling Memory Intensive Operations: For memory-intensive operations, such as denormalization or joining large tables without predicates, StarRocks can intelligently spill intermediate results to disk. This feature prevents Out-Of-Memory (OOM) errors and ensures smooth execution of large data transformation jobs.
-
Practical Benefits: This capability is particularly valuable for materialized views as it offers an efficient way to manage memory-intensive operations, making materialized view refreshes stable.
Use Cases
This might sound good in theory, but how about in practice? Let's look at what industry leaders are doing.
Trip.com's Artnova Platform
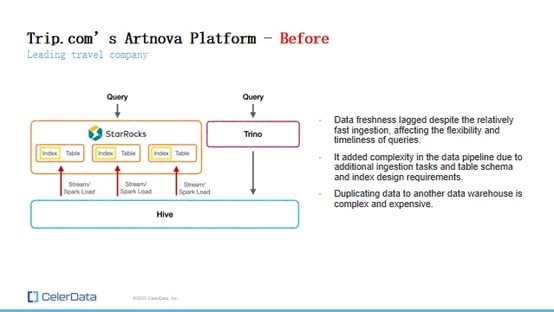
Trip.com's Artnova Platform - Before
Before Switching to StarRocks: Trip.com's internal reporting platform, ArtNova, initially utilized Trino as its primary query engine. Despite its capabilities, Trino struggled with performance in several of Trip.com's key use cases. This led the company to deploy a parallel StarRocks cluster for query acceleration. However, this dual-system approach brought its own set of challenges.
The data ingestion into StarRocks, though fast, led to issues with data freshness and added complexity in maintaining two separate systems. The necessity to keep the table schema and index designs consistent across both systems also increased operational overhead, and having duplicate data in two different warehouses raised concerns regarding data governance.
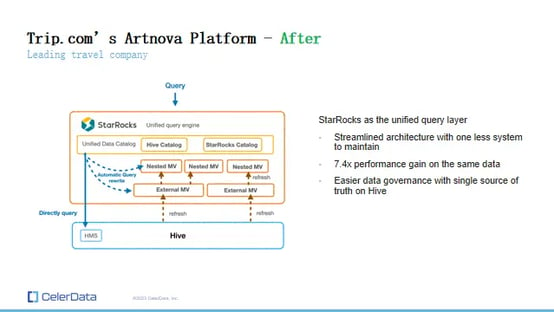
Trip.com's Artnova Platform - After
After Switching to StarRocks: Recognizing these challenges, Trip.com decided to unify its query layer exclusively under StarRocks, eliminating Trino from its stack. This transition brought about a remarkable 7.4x performance gain without even utilizing materialized views.
The simplification of their data architecture led to streamlined operations, with a single, consistent source of truth in their Hive tables. This shift not only alleviated the complexities of data management but also enhanced the timeliness and flexibility of their queries, significantly improving data governance.
ATRenew's Data Lake Analytics
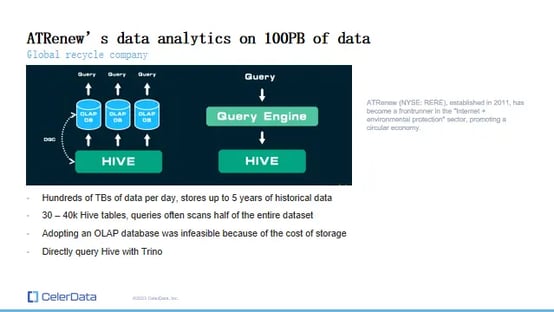
ATRenew's Data Lake Architecture
Before Switching to StarRocks: ATRenew, a company specializing in recycling electronic goods, faced a massive data challenge. With hundreds of terabytes of data being processed daily (with some tables retaining data for up to five years), the sheer volume was daunting.
Their initial setup involved syncing all data into Hive and choosing between ingesting this vast amount of data into an OLAP database or using a query engine to directly query Hive. Trino, their initial choice, proved less efficient, particularly under high concurrency, with queries often scanning half of the entire dataset, making hot-cold data separation impractical.
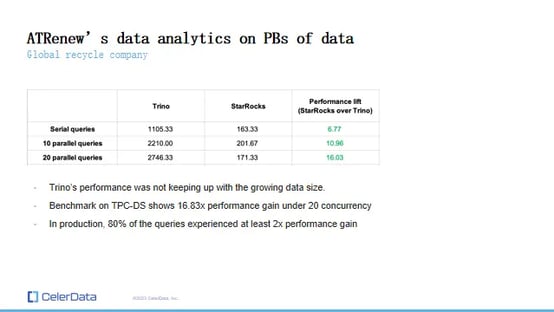
ATRenew's Data Analytics Performance: Trino vs. StarRocks
After Switching to StarRocks: After testing StarRocks, ATRenew observed a significant performance leap. StarRocks demonstrated a 16 to 17x improvement in performance compared to Trino, particularly under 20 concurrent queries. This substantial upgrade led ATRenew to switch to StarRocks in their production environment.
Remarkably, 80% of their queries experienced at least a two-fold increase in performance, a figure achieved without the benefit of cache optimization. ATRenew anticipates further performance boosts once caching is implemented, reinforcing their decision to adopt StarRocks for their extensive data needs.
Social Media Company 'Red'

Red's Analytics Platform - Before
Before Switching to StarRocks: Red, a social media giant with over 200 million monthly active users, initially utilized Presto for querying data on Hive for internal reporting analytics. They also used StarRocks for real-time analytics but had to maintain separate clusters for both Presto and StarRocks.
Managing these multiple technology stacks was operationally taxing. Presto, in particular, presented performance and high availability (HA) concerns due to its leader-follower architecture, which was unsuitable for HA implementations. These issues affected their ability to efficiently process and analyze the enormous scale of data they handled.

Red's Analytics Platform - After
After Switching to StarRocks: Transitioning entirely to StarRocks for both real-time analytics and Hive querying, Red observed a substantial improvement in performance and operational efficiency. They experienced an average 6-7x performance boost on their data lake queries, and a staggering 90% decrease in P90 latency, effectively a tenfold gain.
This consolidation significantly reduced their operational overhead, eliminating the need to maintain a separate Presto cluster. The transition was smooth due to StarRocks’ support for Trino and Presto dialects, which allowed for a rapid migration without the need for extensive SQL modifications.
Questions and Answers
Let's now look at some of the more popular questions asked at our most recent Trino webinar:
Question: Does the information about Trino apply to Presto as well? Are there any significant differences?
Answer: Trino is a fork of Presto, and while they are similar, there are many differences, too numerous to detail here. An article can be provided for those interested in the specifics.
Question: What are the performance differences between StarRocks' internal table query and data lake query?
Answer: The difference is marginal if all of the data is cached, only about 10-15 percent. So, there isn't a significant difference in terms of file format. However, with cold queries, network cost and data lake performance become the bottleneck, which can vary.
Question: What data lakes does StarRocks support?
Answer: StarRocks supports Apache Hive, Hudi, Iceberg, Delta Lake, and a new one called Paimon.
Question: How is the materialized view refreshed in StarRocks?
Answer: The materialized view in StarRocks is refreshed by partition and is not real-time.
Question: Can StarRocks serve as a data lake house?
Answer: This depends on the definition of a data lake house. StarRocks can be used as a query engine for open data lakehouse architectures and as a compute storage-separated data warehouse.
Question: Is StarRocks' capability unique compared to what Doris can do, considering StarRocks was forked from Doris?
Answer: StarRocks has significantly evolved since forking from Doris, with 80% to 90% of the code reworked. The two projects are now completely different.
Question: What does "pipeline-free data analytics" mean on the CelerData site?
Answer: Pipeline-free refers to StarRocks' ability to handle all SQL query workloads directly on the data lake, eliminating the need for a separate data ingestion pipeline for query acceleration.
Question: Can CelerData Cloud do everything StarRocks can for data lake performance?
Answer: Yes, CelerData cloud can do everything StarRocks can for data lake performance, and more.
Question: Does StarRocks plan to ingest data into an open format like Apache Iceberg?
Answer: Iceberg sync and Hive sync are already supported in StarRocks.
Question: What storage was used for the TPC-DS benchmark?
Answer: Object storage was used for the TPC-DS benchmark, not local storage.
Question: How does StarRocks' custom format differ from Iceberg?
Answer: StarRocks' own format is optimized for query performance, providing better performance than other formats. Also, there are more customizations you can do to further improve performance.
Question: Have you compared StarRocks to RisingWave?
Answer: Not extensively, but further investigation can be conducted and information provided later.
Question: Is StarRocks' custom format suitable for low latency append?
Answer: StarRocks can handle real-time analytics, including data appends, updates, upserts, and deletes with better data freshness due to local storage handling.
Question: Where can more information be found about StarRocks' caching layer?
Answer: Information about StarRocks' data cache can be found on the data cache@StarRocks documentation page.
Your Next Step: Try CelerData Cloud

Activate Your CelerData Cloud Free Trial Today
Whether you're a current Trino user looking for alternatives or starting a fresh project, now is the perfect time to put StarRocks' next-generation technology to the test. Right now, CelerData Cloud (and analytics service based on StarRocks) is offering a free 30-day trial with an always-free developer tier. Get started here.