


Join StarRocks Community on Slack
Connect on SlackApache Druid is known for its real-time data ingestion and querying capabilities, especially under high concurrency scenarios. However, many users can attest that Druid's performance has been lagging behind newer database technologies as time has gone on. In this article, we'll dive into the factors behind Druid's fall from grace and where current users can go from here.
What Is Real-Time Analytics?
Real-time analytics refers to the use of, or the capacity to use, available data and resources right as they are produced, rather than at a later time.
Take fraud detection, for instance. Here, the stakes are high as potential financial losses mount with every passing minute that fraudulent activity remains undetected. By employing real-time analytics, businesses can address such threats instantly, preserving resources and protecting their bottom line.
This technology adapts to the unique demands of each business scenario, ensuring that information is not just available but also actionable. Thus, real-time analytics serves as a strategic ally, enabling organizations to make informed decisions swiftly and maintain a competitive edge.
Real-Time Analytics Use Cases
Real-time analytics has found a home in most of the world's largest enterprises and across virtually every industry. It has many practical applications including:
Internal dashboards - Trip.com
A leading travel service provider, trip.com manages a massive number of bookings, customer queries, and operations every day. Real-time analytics plays a pivotal role in their operational efficiency. With internal dashboards powered by real-time data, employees at trip.com can get live updates on bookings, flight statuses, hotel availability, and customer feedback. This enables them to provide swift customer support, optimize their offerings, and make informed business decisions. Read more about trip.com's story here.
Customer-facing dashboards - Xiaohongshu
For Xiaohongshu, a prominent social media platform in Asia with a massive user base, an integral part of their monetization strategy includes advertising. To provide maximum value to their advertisers, Xiaohongshu has implemented a real-time analytics system. Advertisers can log into this system, configure their dashboards, and get an instantaneous view of their ad performance. This empowers them to make quick decisions, optimize their ad strategies, and improve ROI. Read more about Xiaohongshu's story here.
Logistics management - JD Logistics (JDL)
As one of the largest logistics companies in the world, JD Logistics needs a robust system to monitor its vast array of shipments and operations. By leveraging real-time analytics, JDL offers internal dashboards and reports that allow them to track slow shipments, monitor vehicle locations, and ensure timely deliveries. This real-time insight streamlines operations and enhances customer satisfaction by providing accurate delivery estimates and timely updates. Read more about JDL's story here.
Fraud detection - Airbnb
With users spanning across the globe and millions of listings available, it's imperative for Airbnb to detect and prevent fraudulent activities instantly. Through real-time data analysis, Airbnb can quickly spot suspicious patterns, flag questionable bookings, or detect fake reviews, averting potential losses and maintaining user trust. Read more about Airbnb's story here.
Requirements for Modern Real-Time Analytics
While real-time analytics has many benefits, there are also several challenges associated with this technology:
JOINs and denormalization
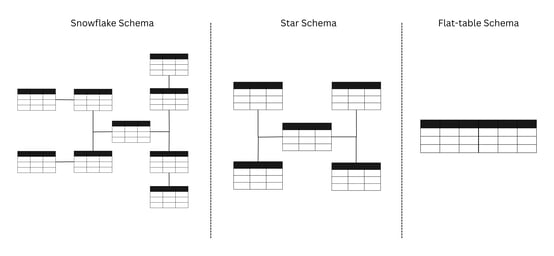
Figure 1: Table Schema Examples
Denormalization is a significant challenge associated with real-time analytics. In nature, data is relational. Most existing solutions lack support for multi-table queries, forcing users to perform denormalization in preprocessing to bypass multi-table JOINs. This adds complexity to the pipeline, is not flexible for business change, and is expensive and ineffective.
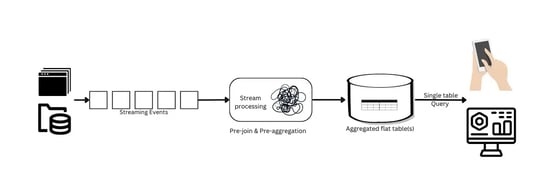
Figure 2: A Complex Real-Time Data Pipeline
Moreover, traditional batch processing tools, while robust for historical data analysis, fail to meet the stringent timing demands of real-time analytics. Instead, users are pushed towards stream processing tools, which, despite their effectiveness in handling real-time data, come with their own set of challenges. They are typically resource-intensive, requiring a substantial investment in infrastructure, and demand a specialized skill set for operation and maintenance.
Denormalization further complicates the data pipeline by fixing data into a single view schema. Any schema change triggers a domino effect, necessitating reconfiguring the entire data pipeline and extensive backfilling of data to fit the new format. This contradicts with the dynamic nature of businesses today. It is imperative that data pipelines are designed for flexibility, enabling them to pivot and adapt as quickly as the businesses they support.
Real-time data updates
The drive for accelerated insights is leading businesses to embrace real-time analytics for more scenarios. The limited ability to perform real-time data updates restricts real-time analytics to append-only scenarios like log analysis, and falls short when it comes to the dynamic nature of modern business processes.
By integrating real-time data updates, businesses unlock a plethora of new possibilities. Consider the field of logistics management: the need to constantly update order statuses is not just a convenience but a necessity. Real-time analytics facilitates this by allowing businesses to track and respond to changes instantaneously, fostering a more adaptable and responsive operational environment.
The advantages of the cloud
While cloud services are often perceived as costly, their inherent elasticity can actually offer cost savings. The cloud's architecture allows for seamless scaling within a distributed system, making it simple to adjust resources to match fluctuating workloads. Analytics services, in particular, benefit from this dynamic scalability as it enables them to meet varying business demands efficiently, ensuring that costs align closely with actual usage.
Why Apache Druid Is Falling Behind
Apache Druid is a high-performance, open-source, real-time analytics database with a column-oriented storage design, developed in Java. Since its debut in 2011, Druid has carved out a reputation for executing sub-second on-the-fly aggregations. Yet, as we surpass a decade since its inception, the data landscape has evolved dramatically. Users now expect even faster query responses, handling larger volumes of data and accommodating more complex, dynamic analytical scenarios.
In this section, we will delve into the evolving demands of contemporary real-time analytics and identify where Apache Druid struggles to keep pace with these advanced requirements. We will also explore alternative solutions and offer insights into when to transition to other technologies that better align with modern data challenges.
Unsatisfactory query performance
Apache Druid's performance was once class-leading, but it has been surpassed by newer OLAP databases with deeper optimizations. Below is the out-of-the-box benchmark result between 3 open-source OLAP databases StarRocks, ClickHouse, and Apache Druid on the SSB single table 100GB benchmark test, where Druid is 8.9x slower than StarRocks.
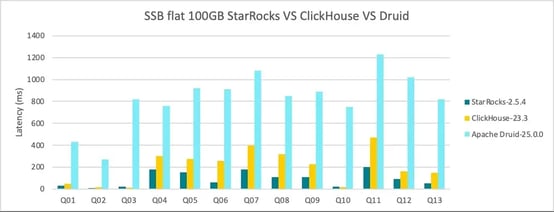
Figure 3: Apache Druid Benchmark Performance
This performance gap is partly due to Druid's Java-based architecture, which does not natively leverage SIMD (Single Instruction, Multiple Data) instruction sets. SIMD optimization is crucial for OLAP workloads to take full advantage of modern multi-core CPUs, giving a significant edge to databases that can utilize them effectively.
Lack of JOIN support
Apache Druid is optimized for single table queries and lacks the capability to execute shuffling operations efficiently along the query path, which are essential for performing JOIN operations at scale. Consequently, when dealing with multiple tables in Apache Druid, denormalization becomes a necessity. This process can be particularly costly and resource-intensive, a factor that's exacerbated in real-time scenarios where the speed and agility of data processing are paramount.
Cloud elasticity
Apache Druid has a deep storage that can take advantage of the low cost of cloud object storage, for example, AWS S3. However, its architecture requires that data be preloaded onto local storage before queries can be executed, as it can not query directly from deep storage. This limitation undermines the potential for dynamic scaling—a key cost-saving feature of cloud computing—resulting in potentially higher expenses due to the need for constant local storage readiness.
Lack of real-time data update support
Apache Druid's design does not cater to scenarios that involve real-time mutable data. For use cases that demand updates to data as they occur, one must resort to a workaround, which can introduce complexity and expense. Options might include appending updates to a large table and resolving them at query time, or preprocessing merges through an external system like Kafka before ingestion into Druid. Each workaround requires considerable engineering work, complicating the data pipeline and making it more error-prone.
Complex architecture
Deploying Apache Druid involves setting up a multi-faceted architecture that includes six core services: the Coordinator, Overlord, Broker, Historical, MiddleManager, and an optional Router service. Additionally, it requires three external dependencies: a deep storage system (such as an external file store), a metadata storage database (typically an RDBMS like PostgreSQL or MySQL), and Apache ZooKeeper for coordination.
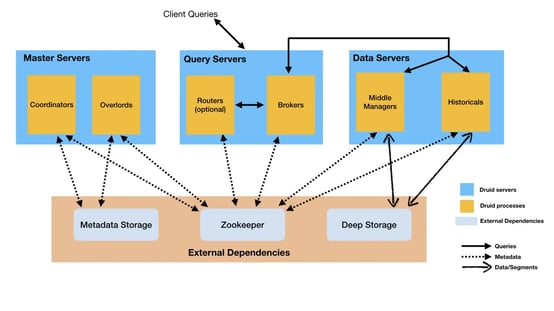
Figure 4: A Complex Apache Druid-Based Architecture
As system complexity increases, so does the operational burden. This complexity can lead to a greater chance of component failures and operational challenges, making the maintenance and usasge of Apache Druid a more demanding task.
An Alternative: StarRocks
StarRocks, a Linux Foundation project, is a real-time MPP OLAP database that is known for its incredible performance on all kinds of SQL queries, and it is built to cater modern real-time analytics workloads.
Class-leading query performance with JOINs
Powered by its MPP compute architecture with in-memory data shuffling, a cost-based optimizer, and SIMD-optimized vector execution, StarRocks is built for executing highly performant multi-table OLAP queries at scale.
.webp?width=554&height=213&name=StarRocks%20Benchmarks%20(1).webp)
Figure 5: StarRocks Benchmark Comparison
In the SSB benchmark test above, StarRocks not only outperforms Apache Druid, but its multi-table query performance is even faster than Druid's single-table queries. This implies that by transitioning to StarRocks, one could eliminate the need for complex denormalization pipelines and still achieve over double the performance gain.
Simple storage-compute-separated design
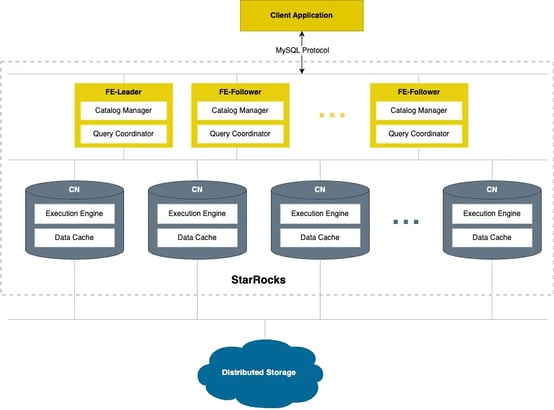
Figure 6: StarRocks' Storage-Compute-Separated Design
StarRocks offers a storage-compute-separated architecture that operates independently of external dependencies. This lightweight design simplifies operations and can dynamically scale to adapt to changing workloads. By enabling direct queries on data stored in distributed systems like AWS S3 and using local disk mainly for caching, StarRocks ensures efficient scalability. This capability to scale without risking data loss during queries is particularly beneficial for modern businesses that demand cost efficiency coupled with rapid query responses.
Primary key index accelerated real-time update
StarRocks' primary key table is ideal for real-time analytics, enabling immediate update and delete operations without degrading query performance. Leveraging a specialized primary key index, it handles upserts and deletes efficiently during data ingestion. This process ensures that only the latest data version is maintained for querying, and streamlining operations by internally transforming all upserts into efficient delete-and-insert sequences.
How Airbnb Does Pipeline-Free Real-Time Analytics
Airbnb's Minerva platform, which handles over 30,000 metrics across 7,000 dimensions and 6+ Petabytes of data, serves diverse teams for varied applications, including A/B testing and data exploration. Initially, Minerva used Apache Druid and Presto as their query layer. The need to denormalize data for multi-table query performance made their pipeline expensive and inflexible, with new metrics requiring days to add.
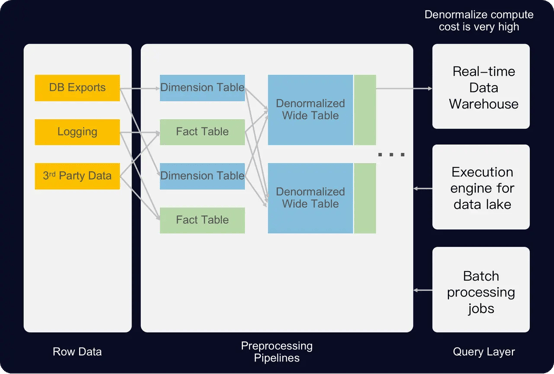
Figure 7: Airbnb's Original Minerva Architecture
To enhance flexibility and efficiency, Airbnb migrated Minerva from Druid and Presto to StarRocks. This new solution shines with its capability to efficiently handle JOIN operations, a strength from its built-in advanced features including a Cost-Based Optimizer, Global Runtime Filters, and SIMD optimizations.
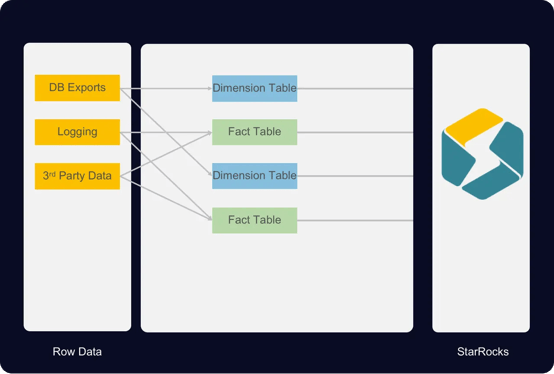
Figure 8: Airbnb's New StarRocks-Based Architecture
With this new approach, data could be kept in a snowflake schema and JOINs performed on-the-fly at query execution. This shift freed Minerva engineers from resource-intensive denormalization. Updates to metrics no longer require data backfill or table reconstruction, resulting in significant cost savings.
Where Apache Druid Users Go From Here
As the demands on real-time analytics grow, Apache Druid is facing significant competition from newer database technologies better suited to today's data-intensive environments. Challenges with Druid's complex query performance, lack of real-time update capabilities, and cloud elasticity are becoming more apparent, urging a shift towards alternatives like StarRocks.
Modern technologies offer improved query performance, adaptability to cloud infrastructures, and more efficient data processing, proving essential for organizations striving to maintain a competitive edge. As enterprises move forward, the transition to these innovative solutions seems not just beneficial but imperative for those aiming to harness the full potential of their real-time data.
If you're ready to take the next step, there has never been a better time. Experience the difference in performance and flexibility for yourself with a free trial of CelerData Cloud. Register now.