


Join StarRocks Community on Slack
Connect on SlackWhat Is Apache Hudi?
Apache Hudi (Hadoop Upserts Deletes and Incrementals) is an open-source data management framework that was developed by Uber in 2016 in response to the need for efficient processing and management of large real-time data volumes. Designed for big data platforms, Apache Hudi has become a cornerstone of Uber's data operations, offering capabilities like updates, inserts, deletes, and incremental processing on platforms like Apache Spark, Apache Hive, and Apache Flink.
Since its inception at Uber, Apache Hudi has evolved to tackle broader big data challenges, offering versatile support for various data formats and query engines, making it a unified data management framework for diverse data workloads. Its open-sourcing by Uber and subsequent adoption by the Apache Software Foundation in 2019 have solidified its role as a leading framework in the big data landscape.
Core Features of Apache Hudi
-
ACID Compliance and Transactional Integrity: Hudi brings ACID (Atomicity, Consistency, Isolation, Durability) compliance to data lakes, ensuring transactional integrity and enabling complex data transformations and rollback capabilities.
-
Efficient Upserts and Deletes: Unlike traditional data lakes where modifying data can be cumbersome and slow, Hudi enables efficient upserts (updating or inserting) and deletes. This feature is crucial for maintaining large datasets where changes are frequent.
-
Incremental Processing: Hudi supports incremental data processing, which allows for processing only the data that has changed, rather than reprocessing entire datasets. This method significantly reduces the computational load and speeds up data ingestion cycles.
-
Scalability: Designed for large-scale operations, Hudi efficiently manages vast amounts of data, demonstrated by its deployment in organizations like ByteDance and Uber, where it handles multiple petabytes of data.
Apache Hudi Architecture
Apache Hudi's architecture can be summarized as follows:
- Write Client: An API for writing batch or streaming data to Hudi tables, enabling record-level insertions, updates, and deletions.
- Delta Streamer: An independent service for merging new changes from various sources like Kafka or AWS S3 into existing datasets in Hudi tables, accommodating both batch and streaming data.
- Hudi Table: Represents datasets managed by Apache Hudi, consisting of multiple versions created through different write operations.
- Indexing: Accelerates data reads and writes by efficiently locating data records.
- Query Engine: Provides SQL query capabilities and native integrations with frameworks like Delta Lake, Apache Spark, and Presto.
- Timeline Server: Manages Hudi dataset metadata to offer a consistent view for optimizing query performance.
Table Types
Copy-On-Write (COW): In this table type, every change to a dataset results in rewriting the file, which ensures that data reads are quick and simple as each read fetches the latest snapshot of the file. This model is ideal for workloads with heavier read operations and fewer write operations.
- For Copy-On-Write Tables, when users update data, the file containing the data is rewritten. This results in high write amplification, but zero read amplification, making it suitable for scenarios with low write and high read frequency.
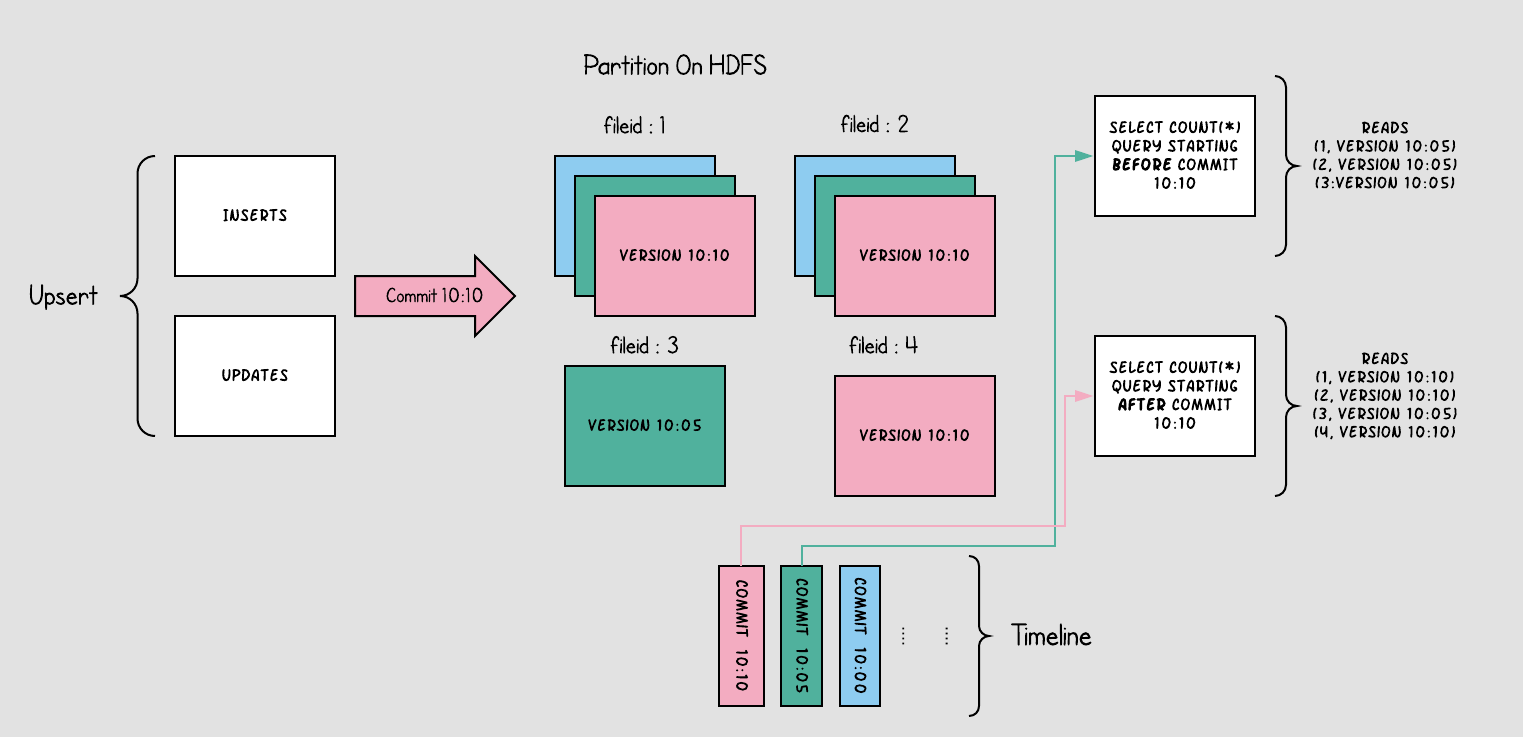 Copy-On-Write
Copy-On-Write
Merge-On-Read (MOR): Merge On Read is optimized for workloads requiring frequent updates. It stores data in a combination of columnar and row-based formats, allowing for faster writes by logging only the changes. These changes are periodically merged with the main dataset, ensuring efficient reads.
- For Merge-On-Read Tables, the overall structure is somewhat similar to an LSM-Tree. User write operations initially go into delta data, which is stored in a row-based format. This delta data can be manually merged into the existing files, organized into a columnar structure like Parquet.
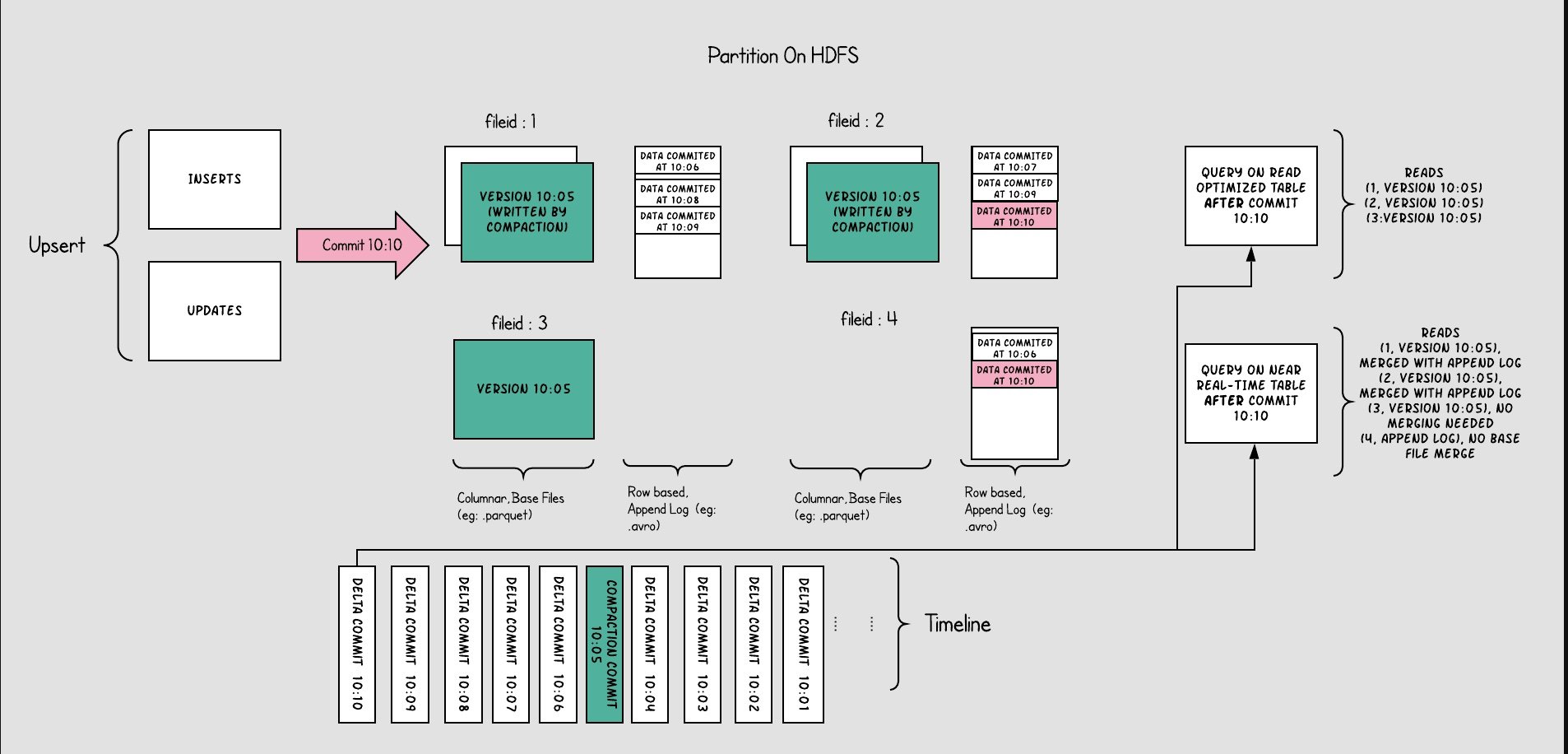 Merge-On-Read (MOR)
Merge-On-Read (MOR)
Query Types
-
Snapshot Queries: These provide a view of the table state at a specific point in time, including all the data up to a particular commit. This is useful for audits and historical analysis.
-
Incremental Queries: Essential for real-time data processing, these queries fetch only the data that has changed since the last commit, facilitating efficient data syncing.
-
Read Optimized Queries: These focus on delivering the fastest read performance by accessing only the compacted and cleaned up base files, which represent the latest snapshots of the data.
Benefits of Apache Hudi
-
Data Consistency: In environments where large volumes of data are processed, Apache Hudi ensures data is accurate, complete, and current. It achieves this through ACID transactions, which maintain data integrity, and mechanisms for resolving conflicts during concurrent updates. This aspect is vital for maintaining reliable data states across large-scale systems.
-
Data Integrity: Apache Hudi prioritizes data integrity, especially when dealing with large-scale data. It employs techniques like checksum verification to prevent data corruption during transfers and updates. Additionally, its data partitioning feature helps manage large datasets by dividing them into manageable segments, thereby mitigating risks of corruption and loss.
-
Schema Flexibility: Hudi supports schema evolution, which is a critical feature for organizations dealing with evolving data models. This flexibility allows them to modify their data schema without disrupting existing processes, facilitating adaptability in dynamic data environments.
-
Performance: In the realm of large datasets, performance is key. Apache Hudi enhances data query and ingestion performance by using indexing for quick data retrieval and incremental data updates. This approach minimizes processing time and resource usage, making data handling more efficient.
-
Integration: Hudi integrates seamlessly with popular big data solutions, enhancing its utility in diverse environments. It supports a variety of storage layers like Amazon S3, Apache HDFS, and Google Cloud Storage, and works well with query engines such as Apache Hive, Presto, and Apache Spark. This makes it a versatile choice for building high-performance, scalable data lakes.
Common Use Cases for Apache Hudi
Apache Hudi finds application in various big data scenarios. Here are several common use cases:
-
Real-Time Data Lakes: Apache Hudi facilitates the construction of real-time data lakes by supporting incremental processing and time-based storage for handling continuously incoming data. It supports multiple file formats and offers query services for fast data access.
-
Financial Transaction Logs: In scenarios requiring the recording of financial transaction logs, Apache Hudi provides transactional writes and updates. It ensures data consistency and reliability, even in cases of failures or exceptions.
-
Media Analytics: Apache Hudi aids in building media analytics platforms for rapid analysis and querying of massive datasets. With Hudi Delta Streamer, various data sources can be integrated into Hudi, allowing custom ETL transformations and data cleansing.
-
Data Quality Monitoring: Apache Hudi is valuable for data quality monitoring by regularly importing source data into Hudi datasets. Leveraging Hudi's compression features and data indexing, it enables quick detection of anomalies and errors, facilitating timely actions.
-
Real-Time ETL: Apache Hudi is used in building real-time ETL pipelines that integrate diverse data sources into Hudi. It supports data cleansing, transformation, aggregation, and direct writes to the target storage system. Thanks to its incremental processing and time-based storage, it responds swiftly to data changes and updates the target storage system in real-time.
Apache Hudi Best Practices
-
Understand Your Data Model and Access Patterns: Before implementing Hudi, it's essential to understand your data model and how your application will access the data. This understanding helps you select the right table design and configuration options for your use case.
-
Use the Appropriate File Format: Hudi supports various file formats like Parquet, ORC, and Avro. Choose the file format based on your use case and performance requirements. For instance, columnar formats like Parquet or ORC are better for low-latency read performance.
-
Optimize the Storage Layer: Hudi's performance heavily relies on the underlying storage layer. Optimizing this layer can significantly improve Hudi's performance. Tips include choosing the right storage medium (e.g., SSDs), optimizing block size and replication factors, and using compression.
-
Monitor Hudi Performance Metrics: Keep an eye on Hudi performance metrics such as query latency, ingestion rate, and storage usage to identify potential bottlenecks and areas for improvement.
-
Partition Your Data: Data partitioning can significantly enhance Hudi's performance. It allows you to filter out unnecessary data based on your query patterns and filter predicates, thus improving query performance. Partitioning also helps maintain a balanced distribution of data across the storage layer and leverages parallelism for faster queries.
-
Use DeltaStreamer for Data Ingestion: Hudi offers a tool called DeltaStreamer that helps efficiently move existing data into Hudi tables. DeltaStreamer can process large volumes of data in parallel and supports various data sources and target formats.
-
Design Hudi Table Primary Keys Carefully: Choosing the right primary key is crucial for setting up Hudi tables. It determines how data is partitioned and how upsert and delete operations are performed. A good design should avoid hotspots and single points of failure, and support high-performance queries and updates.
-
Optimize Write Performance: Write performance is one of the key performance indicators for Hudi. Optimization includes choosing the right writing tool (e.g., Spark or Flink), adjusting batch sizes and parallelism, using Hive metadata caching, etc.
-
Use Hudi Tables for Incremental Computations: Hudi tables support incremental computation, making them highly suitable for real-time computation and stream processing scenarios. By using Hudi APIs, you can easily write incremental computation logic and update results directly back to the tables.
Apache Hudi vs. Apache Iceberg vs. Delta Lake
Currently, Apache Hudi, Apache Iceberg, and Delta Lake stand out as the leading formats specifically designed for data lakes. Each of these solutions addresses specific challenges in data management and offers unique features that cater to different needs in data processing and analytics.
- Delta Lake:
- Strengths:
- ACID Transactions: Offers robust support for ACID transactions, ensuring data integrity.
- Integration with Apache Spark: Deeply integrated with Spark, making it ideal for Spark-based environments.
- Schema Enforcement: Strong support for schema enforcement, maintaining data consistency.
- Limitations:
- Engine Dependency: Primarily designed for Spark, which might limit its use with other processing engines.
- Strengths:
- Apache Hudi:
- Strengths:
- Fast Upsert/Delete: Excels in handling upserts (updating or inserting) and delete operations, which are critical for real-time data processing.
- Copy On Write and Merge On Read: Offers flexibility in data management with these two data storage strategies.
- Stream Processing: Strong capabilities in supporting streaming data, beneficial for real-time analytics.
- Limitations:
- Engine Flexibility: Similar to Delta Lake, it has a strong affinity towards Spark, which may restrict its adaptability with other engines.
- Strengths:
- Apache Iceberg:
- Strengths:
- Extensibility and Abstraction: Highly abstract design, making it adaptable to various computing engines and storage systems.
- File-level Encryption: Unique in offering file-level encryption for enhanced data security.
- Schema Evolution: Supports robust schema evolution without tight coupling to specific compute engines.
- Strengths:
Comparative Summary
- ACID Transactions: Both Delta Lake and Hudi offer strong ACID capabilities, with Iceberg still maturing in this area.
- Schema Management: Delta Lake enforces strict schema rules, while Hudi and Iceberg offer more flexibility in schema evolution.
- Data Processing Compatibility: Delta Lake and Hudi are more Spark-centric, whereas Iceberg provides broader compatibility with various compute engines.
- Real-time Data Handling: Hudi stands out for its efficient handling of real-time data through fast upserts and deletes, a feature currently evolving in Iceberg.
- Community and Ecosystem: Delta Lake and Hudi have more vibrant communities, offering better support and resources for users, whereas Iceberg is growing its presence in this domain.
StarRocks + Apache Hudi = The Modern Open Data Lake
Technical Advantages:
-
Exceptional Performance with Apache Hudi: Our performance evaluations reveal that StarRocks achieves near-local disk performance when integrated with Apache Hudi. This high level of efficiency is a significant technical benefit, demonstrating StarRocks' capability to handle data operations swiftly and effectively.
-
Flexible Query Layer: With StarRocks, there's no lock-in at the query layer. This flexibility means you can switch the query layer if it no longer meets your technical or financial requirements. This adaptability is crucial for evolving data environments and changing business needs.
-
OLAP Database Capabilities: StarRocks extends the functionalities of an OLAP database to data within Apache Hudi. This includes performing JOIN operations and creating materialized views. Moreover, it supports JOINs across multiple data formats, including Apache Iceberg, Apache Hudi, and Apache Hive tables, enhancing data manipulation and analysis capabilities.
-
Broad Tool Compatibility: Many database tools are immediately compatible with StarRocks, thanks to its support for the MySQL wire-compatible protocol. This compatibility means a wide range of existing database tools can be used with StarRocks without the need for extensive configurations or modifications, streamlining the integration process.
If you’re interested in the StarRocks project, have questions, or simply seek to discover solutions or best practices, join our StarRocks community on Slack. It’s a great place to connect with project experts and peers from your industry.
.webp)

