


Join StarRocks Community on Slack
Connect on SlackYour data lakehouse promised flexibility, scalability, and greater cost-effectiveness, but you'd consider yourself lucky if it could deliver at least two of those three most of the time. Your experience isn't unique. In fact, it's all too common.
In this article, we'll examine how to overcome slow query performance, a common yet critical issue for data lakehouses that's the source of these broken promises. We'll then explore five data lakehouse architectures from industry leaders that showcase how enhancing your query performance can lead to more than just compute savings - it will simplify data architecture, strengthen governance, and accelerate development cycles too.
How Bad Query Performance Breaks the Promise of the Lakehouse
Despite functional similarities with data warehouses, data lakehouses often lag in performance, which is caused by data lake query engines not being optimized for high concurrency, low latency workloads. This has forced users to copy their data from the lakehouse into proprietary data warehouses to achieve their desired query performance—through a complex, costly ingestion pipeline that undermines data governance and data freshness.
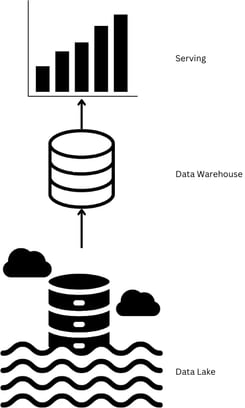 A common, but complex, data lake architecture
A common, but complex, data lake architecture
-
Cost #1: Data ingestion is expensive. Writing data into the proprietary format required by your data warehouse consumes substantial hardware resources and storage redundancy. Beyond just hardware, the process is labor-intensive. Seemingly simple tasks, like matching data types across systems and table/index design in the data warehouse, are resource-heavy. Plus, this data ingestion inevitably adds latency, compromising data freshness.
-
Cost #2: Data ingestion compromises data governance, the very thing that the data lakehouse promises. When there are multiple copies of the same data, ensuring consistent updates across all copies, avoiding discrepancies, and maintaining overall strong data governance are substantial challenges. These aren't mere theoretical concerns but practical issues needing considerable engineering work. If not handled properly, they can jeopardize the reliability of your data-driven decisions.
What Should You Do Instead?
Many enterprises are seeking alternatives that address the shortcomings of their traditional data lake query engines and the added expense of their proprietary data warehouses. Fortunately for these enterprises, modern query engines, optimized for low-latency workloads on open data lakes, now make it feasible to run demanding tasks directly on the data lakehouse.
Let's take a look at the key technologies that are making data warehouse performance on open data lakes possible:
-
MPP with in-memory data shuffling: This approach uses massively parallel processing engines with in-memory data shuffling, bypassing disk persistence used by batch analytical engines to reduce latency and improve real-time query performance.
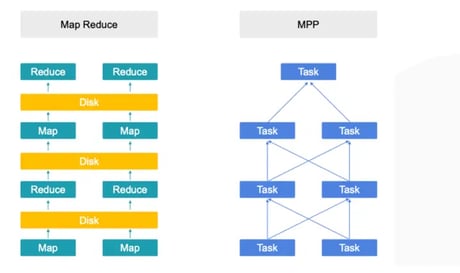 Map Reduce vs. MPP structure
Map Reduce vs. MPP structure
-
Integrated caching frameworks: A hierarchical caching system, combining disk-based and in-memory caching, is integrated within the query engine. This effectively reduces and stabilizes data retrieval latency by shielding it from the unstable and low performance of data lake systems.
Beyond Fast Raw Query Performance: On-Demand Pre-computation Pipelines
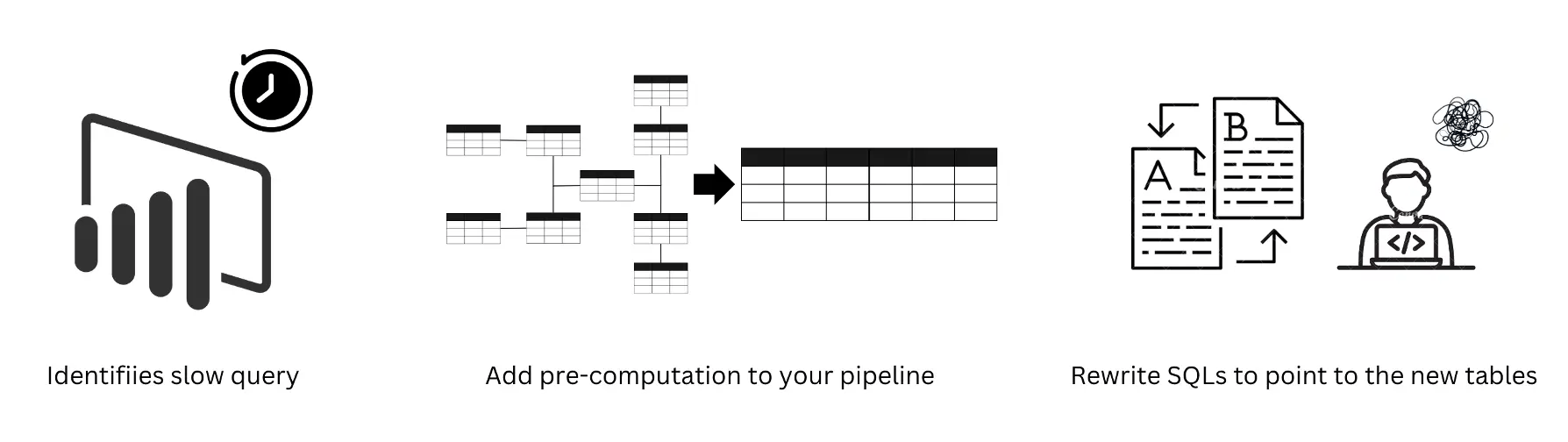 Query optimization process
Query optimization process
As query engines have evolved, there's been a shift in data processing strategies. Originally, due to slower query engines, there was a heavy reliance on pre-computing everything. Now, with faster query engines, the focus has shifted to on-demand pre-computation. This new requirement for flexibility and speed creates a mismatch with traditional pre-computation pipelines, which weren't designed for such on-the-fly computational needs.
New solutions have been designed for modern query engines to embrace on-demand pre-computations, one of which is an advanced materialized view with query rewrite capabilities. Read more about it here: How to Seamlessly Accelerate Data Lake Queries
5 Architectures to Transform Your Lakehouse
This all might sound good in theory, but how does it work against actual production workloads? Let's use five different data lakehouse architectures being employed by industry leaders to see how this all comes together:
-
A leading social media company has shortened its development cycle and improved cost-effectiveness for its trillions of daily records of data by switching to a data lakehouse architecture. Read the case study.
-
A gaming giant is reducing storage costs by 15x while eliminating all pre-aggregations through unifying all workloads on its data lakehouse. Read the case study.
-
A leading travel company has ditched its data warehouse with a data lakehouse query engine and is now experiencing 10x better query performance. Read the case study.
-
An environmental production company 10xed the cost-effectiveness of its analytical system by switching to a modern open-source data lakehouse query engine. Read the case study.
-
An AB testing SAAS platform is unifying its demanding customer-facing workloads on the data lakehouse. Read the case study.
These examples are not unique, and an increasing number of enterprises have already begun making similar changes to finally achieve the flexibility, scalability, and cost-effectiveness that they had adopted a data lake for in the first place.
The Next Step
To experience and reap the benefits as industry leaders have, consider trying CelerData Cloud for free. This move could be the best decision for your engineers, analysts, and overall business, paving the way for unmatched flexibility, scalability, and cost-effectiveness. Get started here.