What is Apache Paimon?
Apache Paimon is an open-source Lakehouse storage framework designed for high-performance stream and batch processing. Initially launched as Flink Table Store (FTS) in January 2022, it was developed within the Apache Flink community to address real-time data lake challenges. The project later transitioned to the Apache Software Foundation (ASF) incubator in March 2023 and was renamed Apache Paimon.
Paimon bridges the gap between streaming and batch analytics, enabling real-time data ingestion, efficient query performance, and a simplified architecture for managing structured data in modern data lakes. It natively integrates with Flink, Spark, Hive, Trino, StarRocks, and other data processing engines.
During its incubation, Apache Paimon addressed several challenges through technical innovation, delivering the following advancements:
- Enhanced Real-Time Ingestion: Paimon offers tools for syncing real-time data from databases like MySQL, handling large-scale data ingestion with low latency. Schema changes are automatically synchronized, ensuring efficient, real-time updates in the data lake.
- Unified Stream-Batch Processing: Paimon integrates with Flink for streaming and Spark for batch processing, allowing consistent handling of both workflows in a unified storage system. This reduces complexity, improves performance, and optimizes resource usage.
- Ecosystem Integration: Paimon supports major open-source data tools, including Flink, Spark, Hive, Trino, StarRocks, Presto, and Doris. This broad integration enables seamless computation and storage within a single platform.
- Advanced Lakehouse Storage: Paimon introduces features like Deletion Vectors and indexing to enhance query performance and support varied workloads, including streaming, batch, and OLAP, with low-latency querying.
Key Capabilities of Apache Paimon
-
Stream and Batch Support: Handles stream updates, batch reads/writes, and change log generation in a unified platform.
-
Data Lake Capabilities: Offers low-cost, highly reliable, and scalable metadata, with all the advantages of data lake storage.
-
Versatile Merge Engines: Provides flexible record update methods, allowing you to choose between retaining the last record, performing partial updates, or aggregating records.
-
Change Log Generation: Generates accurate and complete change logs from any data source, simplifying stream analytics.
-
Rich Table Types: In addition to primary key tables, Paimon supports append-only tables, offering ordered stream reads as an alternative to message queues.
-
Schema Evolution: Fully supports schema evolution, allowing you to rename columns and reorder them as needed.
How Apache Paimon Works
Architecture of Apache Paimon
 Source: paimon.apache.org
Source: paimon.apache.org
Apache Paimon’s architecture is built on Log-Structured Merge (LSM) trees, a storage technique optimized for handling high-throughput writes while maintaining efficient read performance. Instead of directly modifying existing files, Paimon stores changes in immutable segments, periodically merging them to optimize query performance. By leveraging ORC and Parquet for columnar storage, Paimon balances real-time updates with efficient analytical queries. This design makes it particularly well-suited for workloads requiring high-speed ingest, such as change data capture (CDC) pipelines, real-time dashboards, and low-latency OLAP queries.
 Source: paimon.apache.org
Source: paimon.apache.org
Read/Write Capabilities: Paimon offers flexibility in how data is read and written:
- For reading: You can access data from historical snapshots in batch mode, retrieve the latest data in streaming mode, or use a hybrid approach that reads incremental snapshots.
- For writing: Paimon supports streaming synchronization from database change logs (CDC) and bulk insertions or overwrites from offline data sources.
Internal Structure: At its core, Paimon stores data in columnar files within a file system or object storage and uses an LSM tree structure to manage large-scale updates and ensure high-performance queries.
Unified Storage
In streaming engines like Apache Flink, you typically encounter three types of connectors:
- Message Queues: Systems like Apache Kafka are used to ensure low-latency data flow at both the source and intermediary stages of a pipeline.
- OLAP Systems: Tools like ClickHouse receive and process data in streams, making it available for ad-hoc queries.
- Batch Storage: Systems like Apache Hive support traditional batch processing operations, including INSERT OVERWRITE.
Paimon simplifies this by providing a table abstraction that behaves similarly to a traditional database:
- In batch mode: Paimon functions like a Hive table, supporting various batch SQL operations and querying the latest snapshot.
- In streaming mode: It acts like a message queue, allowing you to query it for continuous updates from historical data that never expires.
Basic Concepts
Snapshots
A snapshot captures the state of a table at a specific moment. You can use the latest snapshot to access the most current data, or you can explore previous states through earlier snapshots using time travel.
Partitions
Paimon uses the same partitioning strategy as Apache Hive, dividing tables into sections based on specific column values (e.g., date, city, department). This partitioning helps in managing and querying data more efficiently. If a table has a primary key, the partition key must be a subset of the primary key.
Buckets
Tables, whether partitioned or not, are further divided into buckets. Buckets are determined by hashing one or more columns, and they help organize the data for faster queries. If you don’t specify a bucket key, Paimon uses the primary key (if defined) or the entire record as the bucket key. The number of buckets controls the level of parallelism in processing, but too many buckets can lead to small files and slower reads. Ideally, each bucket should contain around 1GB of data.
Consistency Guarantees
Paimon uses a two-phase commit protocol to ensure that a batch of records is consistently written to the table. Each commit creates up to two snapshots. If multiple writers are modifying a table at the same time, as long as they’re working on different buckets, their changes are processed in sequence. If they modify the same bucket, snapshot isolation is maintained, meaning that while the final table may reflect a mix of changes, no data is lost.
Core Use Cases of Paimon
Paimon currently focuses on three key use cases:
-
CDC Data Ingestion into Data Lakes
Paimon is optimized to make this process simpler and more efficient. With one-click ingestion, you can bring entire databases into the data lake, dramatically reducing the complexity of the architecture. It supports real-time updates and fast querying at a low cost. Additionally, it offers flexible update options, allowing specific columns or different types of aggregate updates to be applied.
-
Building Streaming Pipelines
Paimon can be used to build full streaming pipelines with key features like:
- Generating change logs, which allows streaming reads to access fully updated records—making it easier to build robust streaming pipelines.
- Paimon is also evolving to act like a message queue with a consumer mechanism. The latest version introduces lifecycle management for change logs, letting you define how long they are retained, similar to Kafka (e.g., logs can be stored for a day or more). This creates a lightweight, low-cost streaming pipeline solution.
-
Ultra-Fast OLAP Queries
While the first two use cases ensure real-time data flow, Paimon also supports high-speed OLAP queries for analyzing stored data. By combining Z-Order and indexing, Paimon enables fast data analysis. Its ecosystem supports various query engines like Flink, Spark, StarRocks, and Trino, all of which can efficiently query data stored in Paimon.
Apache Paimon + StarRocks
Apache Paimon seamlessly integrates with StarRocks, enabling real-time analytics on streaming data lakes. This integration provides key benefits:
- Federated Queries: Users can run SQL queries that join Paimon data with StarRocks' internal tables or other external data sources, allowing cross-platform analytics without data duplication.
- Materialized Views for Query Acceleration: StarRocks can automatically create materialized views from frequently accessed Paimon tables, significantly reducing query latency.
- Hot-Cold Data Optimization: Recent data is materialized for ultra-fast queries, while historical data remains in Paimon’s storage layer, reducing costs without sacrificing analytical speed.
- JNI Connector for Lakehouse Compatibility: StarRocks' JNI-based connector ensures compatibility with Java-based storage formats, streamlining data access from Paimon, Hudi, Iceberg, and Hive.
 Source: Using Apache Paimon + StarRocks High-speed Batch and Streaming Lakehouse Analysis
Source: Using Apache Paimon + StarRocks High-speed Batch and Streaming Lakehouse Analysis
Core Scenarios and Technical Principles
- Trino Compatibility: StarRocks achieves 90% Trino SQL compatibility, allowing organizations to migrate existing Trino jobs without changing SQL code. By setting
sql_dialect = "trino", users can run Trino SQL natively on StarRocks. This feature has already been applied in production environments with partners and customers.
- Federated Analytics: StarRocks + Apache Paimon supports complex queries that join multiple data sources and table formats. For instance, users can query Apache Paimon data sources by creating external catalogs and joining them with other tables, including internal StarRocks tables. This enables seamless data integration and federated queries across different systems.
- Transparent Acceleration: Through its materialized view feature, StarRocks can automatically accelerate external table queries by building materialized views of the required tables and partitions in its native format. This optimization is applied without user intervention. SQL queries are automatically rewritten to leverage these materialized views, solving issues where BI tools or SQL queries are difficult to tune manually.
- Data Modeling: StarRocks’ materialized views can be nested to create complex data models across multiple layers (ODS, DWD, DWS, ADS). Data lakes like Apache Paimon are used at the base (ODS layer), with materialized views building higher-level layers. This nested approach simplifies data modeling and accelerates querying across the data pipeline, making StarRocks ideal for large-scale analytics.
- Hot and Cold Data Fusion: StarRocks materialized views support a TTL (Time-To-Live) feature, allowing users to define how long data remains materialized. For instance, partitions for the last three months (hot data) can be materialized, while older partitions (cold data) are queried from the data lake. StarRocks automatically handles the query process, accessing materialized data for hot queries and external table data for cold queries, without requiring users to differentiate between them in their SQL.
- JNI Connector: This connector allows StarRocks (written in C++) to interact with Java-based data lake formats like Apache Paimon, Hudi, AVRO, and RCFile. By abstracting the data conversion process, the JNI Connector simplifies the integration of new data formats, reducing the complexity of adding support for Java-based systems. This improves the flexibility and extensibility of StarRocks in working with various data lakes.
Performance Testing of StarRocks + Apache Paimon Lakehouse Analysis
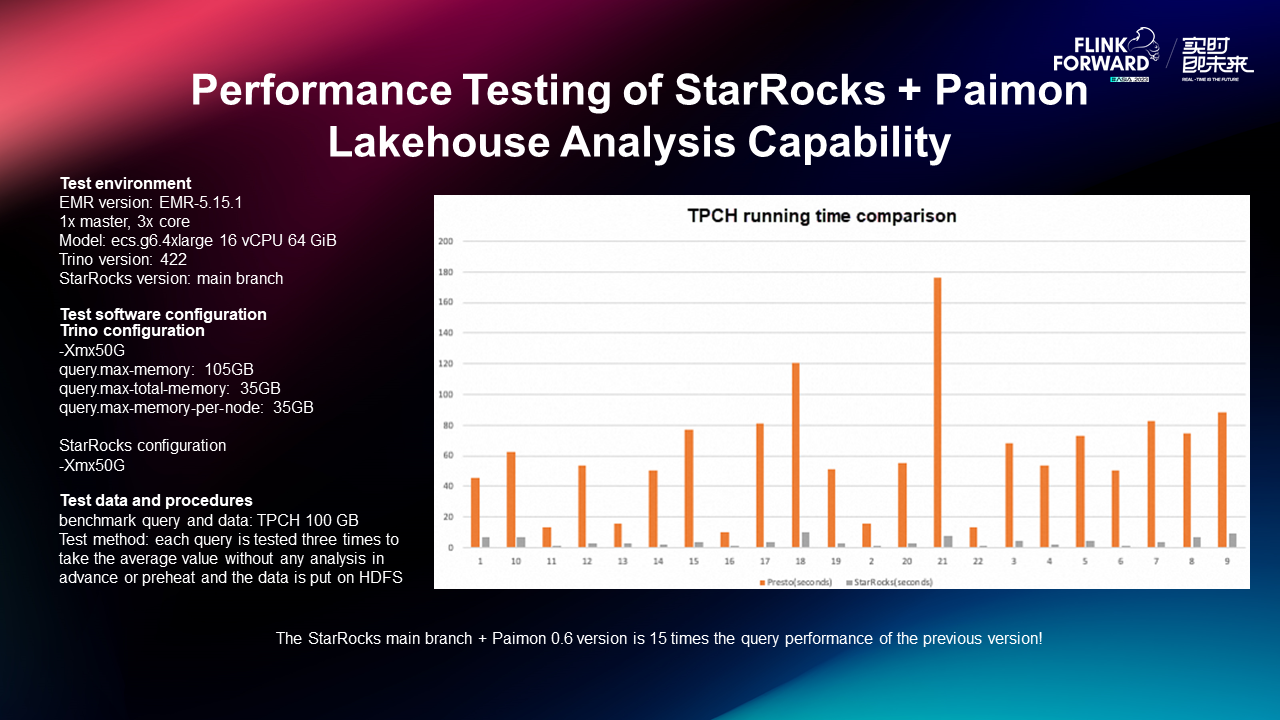
Benchmark tests using the TPC-H 100GB dataset demonstrated significant performance improvements with StarRocks + Apache Paimon. The test environment included 1 master node and 3 core nodes, each with 16 vCPUs and 64GB RAM, running on Amazon EMR with Trino v422. Queries were executed three times per test to measure consistent performance.
Key findings:
- 15x Faster Queries: Compared to previous query engines, StarRocks + Paimon reduced execution times dramatically by leveraging efficient indexing, materialized views, and optimized columnar storage.
- Reduced Data Scanning: Using Z-order indexing and data pruning, StarRocks scanned up to 80% less data per query, improving performance.
- Minimal Preprocessing Overhead: Unlike batch processing solutions that require periodic ETL, Paimon’s real-time CDC ingestion keeps data fresh without additional compute-intensive transformations.
For more details, please read "Using Apache Paimon + StarRocks for High-Speed Batch and Streaming Lakehouse Analysis", which is organized from Riyu Wang’s presentation at FFA (Flink Forward Asia) 2023.
Real-World Application: How Ele.me Drives Growth with Flink, Paimon, and StarRocks
Ele.me, a leading local life service platform, focuses on online food delivery, new retail, instant logistics, and restaurant supply chain services. It has transformed food delivery into a mainstream dining option in China, covering 670 cities and over 1,000 counties, with 3.4 million online restaurants and 260 million users. To support this vast operation, Ele.me has evolved its data infrastructure, leveraging Flink, Paimon, and StarRocks to drive real-time data applications.
Real-Time Data Warehouse Evolution
Ele.me's real-time data warehouse supports various business-critical functions, including:
- Real-time ETL: Real-time data ingestion, modeling, and traffic attribution.
- Real-time Reporting: Supporting live marketing activities, merchant business analysis, real-time traffic dashboards, big promotions, and A/B testing.
- Real-time Business Integration: Coordinating logistics in real-time, delivering personalized recommendations, syncing IoT information, and real-time fraud detection.
- Real-time Monitoring and Compensation: Data verification, business diagnostics and alerts, and server anomaly monitoring.
Leveraging Flink, Paimon, and StarRocks for Real-Time Data Applications
To tackle the challenges of scaling its real-time data applications, Ele.me strategically integrated the following technologies:
1. Flink for Real-Time Processing
Flink handles real-time data processing, enabling complex event and stream processing for a wide range of data sources. It supports high-velocity data streams, ensuring low-latency performance, essential for making real-time business decisions.
2. Paimon for Streaming Lakehouse Storage
Paimon is the core of Ele.me’s streaming lakehouse architecture, enabling efficient data storage for real-time data processing. It supports real-time read and write operations, facilitating up-to-date data for analytics. Key features include:
- Seamless Integration with Data Lakes: Paimon allows for flexible and scalable data storage, essential for real-time applications.
- Efficient Data Management: Paimon supports real-time data updates, which is critical for maintaining data accuracy across different business use cases.
3. StarRocks for High-Performance Analytics
StarRocks is integrated as a core OLAP engine, providing high-performance analytical capabilities on top of Paimon data. It offers several significant benefits:
- Enhanced Query Performance: StarRocks enables fast analytical queries on large datasets, supporting high-concurrency scenarios crucial for real-time analytics.
- Low Latency: By supporting efficient data querying and complex analytics, StarRocks ensures that real-time data is quickly accessible for business intelligence and operational analytics.
- Seamless Data Integration: With its ability to connect directly with Paimon and other data sources, StarRocks simplifies the architecture and improves data accessibility.
Business Impact
The integration of Flink, Paimon, and StarRocks has led to substantial improvements in Ele.me’s data infrastructure:
- Reduced Data Latency: The real-time data ingestion and processing capabilities have significantly reduced data latency, enabling near-real-time data availability for analytics.
- Improved Analytical Efficiency: With StarRocks, complex analytical queries can be executed more efficiently, reducing the time required to gain insights from large datasets.
- Cost and Resource Optimization: The combination of Paimon for storage and StarRocks for analytics has helped optimize resource usage, reducing overall data processing costs while maintaining high performance.
Conclusion
The blog covered the essential aspects of Apache Paimon, including its architecture, features, and setup process. Apache Paimon stands out in data streaming and storage due to its high-throughput data writing and low-latency queries. The tool's compatibility with common computing engines like Alibaba Cloud E-MapReduce (EMR) enhances its utility. Apache Paimon significantly improves data processing frameworks and simplifies large-scale data operations. Readers are encouraged to explore and experiment with Apache Paimon to unlock its full potential in real-time data processing and analytics.





.jpg)