


Seeking Data Lakehouse Solutions?
Connect on SlackUnderstanding Unity Catalog and Its Place in the Data Ecosystem
The modern data landscape is increasingly fragmented. Organizations operate across multiple clouds, hybrid environments, and diverse data processing engines, generating structured, semi-structured, and unstructured data. Managing this data efficiently requires governance, access control, lineage tracking, and discoverability—all of which are the primary functions of a data catalog.
However, not all data catalogs serve the same purpose. Some are technical metastores, designed to store metadata for query engines, while others focus on business metadata, helping analysts and engineers discover and document data assets. With new open table formats like Apache Iceberg, Apache Hudi, and Delta Lake, data catalogs have taken on an even greater role in ensuring seamless interoperability across platforms.
One of the most comprehensive solutions in this space is Unity Catalog, launched by Databricks in 2021. Unlike traditional metastores, Unity Catalog is designed to be a unified and interoperable governance layer that spans both structured and unstructured data assets, including AI models and functions. It streamlines governance by centralizing access control, auditing, lineage tracking, and data discovery across all workspaces. Before its introduction, governance in many organizations was fragmented, with different environments managing access policies and metadata independently, leading to inconsistencies and security challenges.
Recognizing the need for open and standardized governance, Databricks open-sourced Unity Catalog in June 2024, making it the first open-source catalog capable of managing data and AI assets across multiple clouds, formats, and compute engines. This move aimed to break vendor lock-in, enhance interoperability with table formats like Delta, Iceberg, and Hudi, and provide organizations with a governance framework that is both flexible and scalable. By opening Unity Catalog to the broader community, Databricks has positioned it as a foundational component of the modern data ecosystem, ensuring that governance is no longer an obstacle but an enabler of data-driven innovation.
Why Was Unity Catalog Open-Sourced?
Databricks has a long history of championing open source, contributing to major projects like Apache Spark, MLflow, and Delta Lake. Unity Catalog was initially developed to solve the limitations of the Hive Metastore (HMS), which, despite being widely adopted, lacked several critical capabilities:
- No built-in governance for AI assets and unstructured data (e.g., PDFs, images, models)
- Inflexible access control that required workspace-level management rather than centralized enforcement
- Limited interoperability with modern table formats and cloud-native storage solutions
- No standardized APIs for cross-platform access
The Design Motivation Behind Unity Catalog
Unity Catalog was built to act as a unified governance layer for structured, semi-structured, and unstructured data. Unlike Hive Metastore, which primarily serves as a registry for SQL tables, Unity Catalog extends governance to AI models, user-defined functions (UDFs), and even file-based data assets.
The decision to open-source Unity Catalog was driven by four key goals:
- Breaking Vendor Lock-In – Many organizations want to manage metadata across multiple clouds, compute engines, and storage formats. Open-sourcing Unity Catalog allows broader adoption beyond the Databricks ecosystem.
- Enhancing Open Standards – By supporting Delta Lake, Iceberg, Parquet, CSV, and JSON, Unity Catalog promotes multi-format interoperability, making it easier to work across different storage backends.
- Improving Data & AI Governance – Unity Catalog integrates access control with identity federation, ensuring security policies are enforced across all data types, not just tabular datasets.
- Encouraging Innovation – Open-sourcing the Unity APIs allows for community-driven improvements, much like how Delta Lake evolved into a widely adopted open table format.
With over 10,000 organizations using Unity Catalog in production, Databricks felt confident that the core architecture and APIs were mature enough to be released as an open-source project.
.png?width=443&height=512&name=unity-catalog-blog-image%20(1).png)
Source Databricks Open Sourcing Unity Catalog
The decision to open-source Unity Catalog was driven by confidence in its technical maturity. With over 10,000 customers already running Unity Catalog in production, Databricks felt it was the right time to contribute it to the open-source community, enabling wider adoption and further innovation.
Additionally, the Unity Catalog logo itself symbolizes its core functionality: squares representing structured data (tables), triangles symbolizing AI-related assets (models and functions), and hexagons denoting unstructured data (volumes). This visual representation highlights Unity Catalog’s ability to bridge different types of data assets in a seamless manner.
By opening up Unity Catalog, Databricks is not just sharing its governance technology with the community but also advancing the broader vision of an open lakehouse architecture where governance is no longer a bottleneck but a foundational enabler of data-driven innovation.
What Data Challenges Does Databricks Unity Catalog Solve?
Before Unity Catalog, companies often faced governance headaches due to several critical issues:
Fragmented Data Governance
Data governance was often managed separately within each workspace, requiring teams to configure policies independently for different environments. This led to inconsistencies, redundant efforts, and security vulnerabilities. Managing data in silos made it difficult to enforce standardized governance practices across an organization.
Complex Identity and Access Management
User identity and access control were cumbersome to manage across multiple workspaces and platforms. Each system required separate access configurations, leading to administrative overhead and potential misconfigurations. Ensuring consistency in access control policies was a significant challenge.
Lack of Data Lineage and Quality Tracking
Understanding how data flows through different transformations and pipelines was difficult. Without clear lineage tracking, teams struggled to trace the origin and transformations of datasets, making debugging, compliance, and performance optimization more complicated. Maintaining data quality and ensuring consistency across various teams was another persistent issue.
Regulatory Compliance and Security
Regulations such as GDPR, CCPA, and industry-specific standards require stringent data governance, access control, and auditability. However, enforcing these requirements in a distributed data environment with fragmented governance structures was difficult, increasing the risk of non-compliance and data breaches.
Scaling Governance in Multi-Cloud Environments
As organizations expanded across cloud providers such as AWS, Azure, and GCP, ensuring a consistent governance framework became increasingly complex. Different cloud environments introduced variations in how data was accessed and managed, making it difficult to implement a unified governance strategy at scale.
What Are the Key Components of Databricks Unity Catalog?
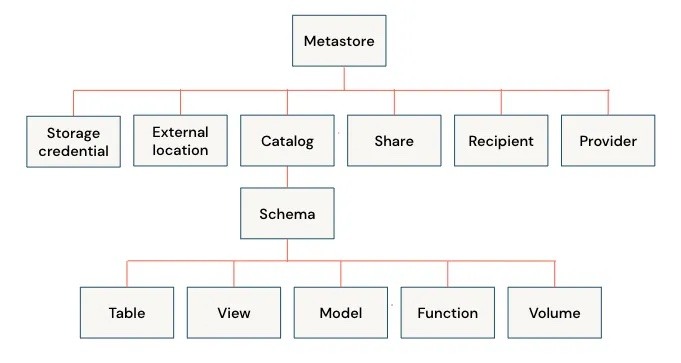
Metastore: The Foundation of Governance
The metastore serves as the top-level container for metadata management and access control. Unlike traditional Hive Metastore (HMS), which operates at a per-cluster or per-workspace level, Unity Catalog’s metastore is globally accessible across all Databricks workspaces in an organization.
Key Advantages of the Unity Metastore:
- Centralized governance: Organizations can enforce access control, policies, and metadata management consistently across all workspaces.
- Multi-cloud support: Unity Catalog’s metastore is cloud-agnostic, enabling seamless governance across AWS, Azure, and GCP.
- Support for multiple table formats: Unlike HMS, which was primarily built for Hive tables, Unity Catalog natively supports Delta Lake, Apache Iceberg, Apache Hudi, and Parquet.
Catalog: Logical Grouping of Data
A catalog in Unity Catalog is a logical collection of schemas (databases). It organizes and isolates data assets based on business domains, teams, or environments (such as development, staging, and production).
Key Benefits of Catalogs:
- Hierarchical Organization: Instead of managing all schemas globally, catalogs provide a structured way to group and manage data assets efficiently.
- Inherits Metastore Policies: Access control and compliance policies applied at the metastore level cascade down to all catalogs within it.
- Multi-tenancy support: Different business units or teams can operate within separate catalogs while still adhering to centralized governance policies.
Schemas (Databases): Organizing Tables and Views
A schema, also referred to as a database, is a logical collection of tables and views within a catalog. Schemas further help structure and categorize data assets within an organization.
Key Features of Schemas:
- Inherits governance policies: Access control and security rules applied at the catalog level automatically extend to all schemas within it.
- Supports structured and unstructured data: Unlike traditional schemas that only store tabular data, Unity Catalog allows for the management of unstructured data assets (images, PDFs, models, etc.).
- Seamless interoperability: Organizations can store Iceberg, Delta, Hudi, and Parquet tables under the same schema and govern them uniformly.
Tables and Views: Core Data Assets
Tables in Unity Catalog are structured collections of data stored in a table format such as Delta Lake, Iceberg, or Hudi. Unity Catalog also supports views, which are virtual tables derived from one or more tables through SQL queries.
Key Enhancements Over Traditional Data Management Approaches:
- Managed and External Tables:
- Managed Tables: Stored directly in Databricks-managed storage, with Unity Catalog handling lifecycle management (ownership, retention, security).
- External Tables: Stored in external cloud storage (S3, ADLS, GCS), allowing organizations to bring their own data while maintaining Unity Catalog governance.
- Automated Lineage Tracking: Every transformation, read, and write operation in a table or view is automatically tracked, providing full visibility into data movement and transformations.
Identity Federation: Unified User and Access Management
Identity Federation in Unity Catalog simplifies authentication and access management across all workspaces and cloud providers. Rather than managing access at the workspace level, Unity Catalog federates identities at the account level using industry standards such as OAuth, SCIM, and IAM policies.
Benefits of Identity Federation:
- Single Identity, Multi-Workspace Access: A user’s permissions remain consistent across Databricks workspaces rather than needing to be configured separately for each one.
- Integration with Enterprise IAM Systems: Supports integration with identity providers like Okta, Azure AD, and AWS IAM, streamlining authentication.
- Reduced Administrative Overhead: Admins define permissions once at the account level, and they are automatically enforced across all workspaces.
Access Control Lists (ACLs): Fine-Grained Permissions
Unity Catalog enables fine-grained, role-based access control (RBAC) through Access Control Lists (ACLs).
How ACLs Work in Unity Catalog:
- Granular Permissions: Access control can be applied at catalog, schema, table, or column levels.
- Role-Based Enforcement: Users and groups are assigned specific privileges like SELECT, INSERT, UPDATE, DELETE, and MODIFY on data objects.
- Storage Credential Integration: When a user queries an external table, Unity Catalog automatically vends temporary storage credentials, ensuring secure access.
Unlike legacy metastores, Unity Catalog’s ACLs extend beyond tabular data to include AI models, user-defined functions (UDFs), and unstructured data assets.
Data Lineage and Quality Monitoring: Ensuring Data Trustworthiness
One of the most powerful capabilities in Unity Catalog is automated lineage tracking and data quality monitoring.
Data Lineage in Unity Catalog:
- Tracks End-to-End Data Movement: From ingestion to transformation to consumption, Unity Catalog logs all data dependencies.
- Column-Level Lineage: Users can trace lineage not just at the table level but also at the column level, which is essential for debugging, compliance, and impact analysis.
- Cross-Engine Lineage: Unity Catalog captures lineage from Spark, SQL-based workloads, and AI/ML models, making it one of the few catalogs that bridge data and AI governance.
Data Quality Monitoring:
- Schema Evolution & Versioning: Unity Catalog tracks schema changes over time, preventing accidental breaking changes.
- Data Freshness & Integrity Checks: Built-in monitoring features help detect anomalies, flag outdated data, and enforce data quality policies.
How Does Unity Catalog Compare to Other Catalogs?
Choosing the right catalog depends on your use case, architectural constraints, and governance needs. To understand where Unity Catalog fits, let's compare it to Apache Polaris, DataHub, AWS Glue, and other catalog offerings.
| Feature | Unity Catalog OSS | Unity Catalog (Databricks) | Apache Polaris | AWS Glue | DataHub | Atlan |
|---|---|---|---|---|---|---|
| Open Table Format Support | Delta, Iceberg, Hudi | Delta, Iceberg (Uniform for Hudi) | Iceberg Only | Delta, Iceberg, Hudi | Delta, Iceberg, Hudi | Delta, Iceberg |
| Unstructured Data Governance | ✅ Volumes for files | ✅ Volumes for files | ❌ No | ❌ No | ❌ No | ❌ No |
| Identity Federation | ✅ OAuth & IAM | ✅ SCIM, OAuth, IAM | ⚠️ OAuth Client Secrets | ✅ AWS IAM | ✅ OAuth | ✅ OAuth |
| Query Engine Compatibility | Spark, DuckDB, Daft | Spark, DuckDB, Trino | Iceberg-compatible only | AWS services (Athena, Redshift) | Multiple | Multiple |
| Data Lineage | ❌ No | ✅ Spark, SQL lineage | ❌ No | ❌ No | ✅ Rich lineage | ✅ Rich lineage |
| Data Discovery & Search | 🔍 Basic schema browsing | 🔍 AI-enhanced search | 🔍 Basic metadata search | 🔍 Basic metadata search | 🔍 Advanced search, filtering | 🔍 Advanced search, filtering |
| Access Control | ✅ Storage-based auth | ✅ Storage-based auth | ✅ RBAC | ❌ Metadata only | ❌ Metadata only | ❌ Metadata only |
Key Observations
- Unity Catalog (Databricks product) is the most feature-rich for organizations using Databricks. It offers comprehensive governance across structured and unstructured data, native identity federation, and deep integration with query engines like Spark and Trino.
- Unity Catalog OSS is still evolving and currently lacks advanced lineage tracking and discovery features, though it supports multiple table formats.
- Apache Polaris is a strong Iceberg-native catalog, making it ideal for Iceberg-heavy deployments. However, it lacks support for Delta Lake or Hudi.
- AWS Glue remains tightly coupled with the AWS ecosystem and functions primarily as a metastore rather than a full-fledged data governance solution.
- DataHub and Atlan excel as business-focused catalogs, emphasizing discovery, documentation, and data governance across diverse data sources.
StarRocks + Unity Catalog: Unified Governance and High-Performance Analytics
As organizations scale their data infrastructure, they often face challenges in balancing performance, interoperability, and governance. While modern query engines provide fast analytics, ensuring consistent access control, metadata management, and interoperability across diverse storage formats remains a challenge. StarRocks and Unity Catalog address these concerns by integrating high-performance SQL querying with centralized governance and metadata management.
How Unity Catalog and StarRocks Work Together
Unity Catalog provides a centralized metadata and governance layer for managing structured, semi-structured, and unstructured data. It enforces fine-grained access control, maintains data lineage, and supports multiple table formats such as Delta Lake, Apache Iceberg, and Apache Hudi.
StarRocks, an open-source analytical database, is optimized for low-latency, high-concurrency queries on large datasets. It integrates with Delta Lake via Delta Kernel Java, allowing it to efficiently query Delta tables managed within Unity Catalog.
This combination enables:
-
Interoperability Across Table Formats
- Unity Catalog unifies metadata and governance for Delta Lake, Iceberg, and Hudi.
- StarRocks can query Delta tables directly, ensuring efficient access without additional ETL pipelines.
-
Centralized Security and Access Control
- Unity Catalog enforces consistent access policies across multiple compute engines, ensuring that StarRocks queries adhere to predefined identity and access management rules.
- This eliminates the need for managing separate access control lists (ACLs) per query engine.
-
High-Performance Query Execution
- StarRocks leverages vectorized execution and cost-based optimization to accelerate SQL queries on large-scale tabular datasets.
- When querying Delta tables, StarRocks benefits from Unity Catalog’s metadata layer, reducing the need for expensive table scans.
-
Cross-Engine Federated Analytics
- StarRocks supports federated queries, enabling users to join Delta tables managed by Unity Catalog with data from other sources, such as object storage or data warehouses.
- This allows organizations to run complex analytical queries without duplicating data.
Conclusion
Databricks Unity Catalog is a powerful open-source metadata and governance solution that streamlines data access, security, and lineage tracking. By supporting open table formats and multi-cloud environments, it provides a scalable governance layer for modern data lakes and lakehouses.
With interoperability across query engines like StarRocks, Trino, and Spark, organizations can unlock new levels of performance, real-time analytics, and AI-driven workloads while maintaining a strong governance posture.
StarRocks, as a high-performance analytical engine, extends Unity Catalog’s capabilities, making it easier to query governed data at scale. Whether for BI, federated analytics, or real-time AI, StarRocks and Unity Catalog together offer an efficient and scalable solution for the modern data stack.
FAQ
How does Unity Catalog enforce access control?
Unity Catalog provides fine-grained access control through role-based access control (RBAC) and attribute-based access control (ABAC). It supports:
- Permissions at multiple levels (catalog, schema, table, and column).
- Integration with enterprise identity providers (Okta, Azure AD, AWS IAM) to centralize authentication.
- Storage-based access control, where query engines must request credentials to access underlying data, preventing unauthorized bypass.
This ensures consistent security enforcement across compute engines such as Spark, Trino, DuckDB, and StarRocks.
Can Unity Catalog manage both structured and unstructured data?
Yes, Unity Catalog governs structured, semi-structured, and unstructured data. It extends beyond traditional table metadata to manage:
- Delta, Iceberg, and Hudi tables for structured data.
- AI models, user-defined functions (UDFs), and machine learning artifacts.
- Files (e.g., PDFs, images, logs) using Unity Catalog Volumes for unstructured data governance.
How does Unity Catalog integrate with StarRocks?
StarRocks, a high-performance analytical database, integrates with Unity Catalog by:
- Querying Delta Lake tables via Delta Kernel Java, ensuring interoperability.
- Enforcing access control through Unity Catalog, maintaining consistent governance across compute engines.
- Federating queries, allowing StarRocks to analyze data from multiple formats managed by Unity Catalog without requiring ETL processes.
This integration enables fast, real-time analytics on governed data stored across multiple table formats.
Does Unity Catalog support real-time data processing?
Yes, Unity Catalog supports real-time data management through Delta Lake and Apache Hudi:
- Delta Lake with Structured Streaming enables real-time ingestion and querying.
- Hudi’s incremental processing allows upserts and deletes, making it efficient for change data capture (CDC) workloads.
- StarRocks and Trino integration provide low-latency queries on streaming data.
This makes Unity Catalog well-suited for real-time analytics, data pipelines, and AI applications.
Can Unity Catalog be used in multi-cloud environments?
Yes, Unity Catalog is cloud-agnostic and supports:
- Multi-cloud governance across AWS, Azure, and GCP.
- Cross-platform interoperability with open table formats (Delta, Iceberg, Hudi).
- Identity federation to unify user authentication across cloud environments.
This ensures consistent metadata management, access control, and lineage tracking across different cloud providers.
What query engines can use Unity Catalog?
Unity Catalog integrates with:
- Spark (Databricks-managed and OSS Spark).
- Trino for federated SQL analytics.
- DuckDB for local analytics.
- StarRocks for high-performance, real-time queries.
Because it supports open table formats, Unity Catalog can work with any engine that supports Delta, Iceberg, or Hudi.
How does Unity Catalog improve data lineage tracking?
Unity Catalog automatically tracks lineage for data transformations, providing:
- Table- and column-level lineage, capturing how data moves and changes.
- Cross-engine lineage, integrating with SQL, Spark, and AI pipelines.
- Impact analysis, allowing users to track dependencies and changes in data workflows.
This ensures transparency in data transformations for debugging, compliance, and governance.
Can Unity Catalog replace Hive Metastore?
Yes, Unity Catalog is a modern alternative to Hive Metastore (HMS), offering:
- Centralized governance across multiple clouds, unlike HMS, which is tied to on-prem Hadoop clusters.
- Support for Delta, Iceberg, and Hudi, whereas HMS was designed for Hive tables.
- Advanced access control and identity federation, ensuring better security than HMS’s metadata-only governance.
Organizations migrating from HMS to Unity Catalog benefit from stronger interoperability, access control, and scalability.
What storage formats are supported in Unity Catalog?
Unity Catalog supports:
- Delta Lake – Optimized for transactional data lakes.
- Apache Iceberg – Ideal for multi-engine lakehouse environments.
- Apache Hudi – Optimized for incremental processing and real-time ingestion.
This flexibility allows organizations to use the best table format for their specific needs while maintaining governance.
How does Unity Catalog simplify governance across multiple teams?
Unity Catalog provides:
- Hierarchical governance with catalogs, schemas, and tables to organize data by business units, projects, or compliance zones.
- Multi-tenancy support, allowing different teams to operate under separate catalogs while following enterprise-wide governance policies.
- Role-based access control (RBAC) for managing permissions at different levels (organization, business unit, project).
This makes it easier to enforce security, manage access, and track data usage across an enterprise.
Can Unity Catalog be used with non-Databricks environments?
Yes, the open-source version of Unity Catalog can be used outside of Databricks, providing:
- Standardized metadata management across multiple platforms.
- Integration with open table formats and external query engines.
- Governance capabilities that extend beyond Databricks-native services.
However, some advanced features like AI-driven discovery and managed access control are exclusive to the Databricks-managed version.
What role does Unity Catalog play in AI and machine learning governance?
Unity Catalog extends data governance to AI models and ML artifacts, including:
- Tracking lineage of ML models, ensuring reproducibility and compliance.
- Governing access to model inputs and outputs, preventing unauthorized usage.
- Managing feature stores and training datasets, ensuring consistent metadata for ML pipelines.
This integration helps organizations maintain governance over AI and ML workloads in regulated environments.
How does Unity Catalog handle schema evolution?
Unity Catalog supports:
- Schema enforcement to prevent breaking changes in production.
- Versioning of schema changes, allowing rollback if needed.
- Column-level tracking to maintain compatibility across data transformations.
This ensures data consistency while allowing for controlled schema modifications.
.webp)

