


Questions About Pipeline-Free Analytics?
Connect on SlackWhat is a Data Pipeline?
A data pipeline is a set of processes and technologies that systematically move data from one system to another. It plays a vital role in gathering, transforming, and either storing or utilizing data for diverse purposes like analysis, reporting, or operational functions.
How Data Pipelines Work:
- Data Sources: The starting points of a data pipeline. These can be databases, cloud storage, IoT devices, web APIs, or any other sources where data originates.
- Data Ingestion: The process of collecting data from various sources. This can involve batch processing (collecting data at scheduled intervals) or real-time streaming (collecting data as it is generated).
- Data Processing and Transformation: Once the data is ingested, it often needs to be cleaned, validated, transformed, or enriched to make it usable. This may involve converting data formats, enriching data with additional sources, filtering, or aggregating.
- Data Storage: After processing, data is typically stored in a data warehouse, data lake, or other storage systems. This is where it becomes accessible for analysis and decision-making.
- Data Consumption: The final step where the processed and stored data is used for various purposes like business intelligence, reporting, machine learning models, or directly in business operations.
- Orchestration and Workflow Management: This involves managing the sequence of data processing tasks, ensuring that they execute in an orderly and reliable manner. Tools like Apache Airflow are often used for this purpose.
- Monitoring and Maintenance: Constant monitoring is essential to ensure the pipeline functions smoothly. This includes tracking data flow, performance, and error handling.
- Security and Compliance: Ensuring data privacy, security, and compliance with relevant laws and regulations throughout the pipeline.
- Scalability and Flexibility: The architecture should be able to scale with the growing data needs of the organization and be flexible enough to adapt to changes in data sources, formats, and business requirements.
Data Pipelines: Types & Their Roles
Batch Data Pipelines:
- Description: This involves processing large volumes of data at specific intervals. The process includes data collection, validation, pre-processing, storing in an intermediate database, and then executing scripts for analysis and transformation.
- Use Cases: Examples include nightly data backups, daily reports, or situations where processing demands significant computational resources, making it more economical to run at specific intervals.
Streaming (or Real-time) Data Pipelines:
- Description: These pipelines focus on processing data in real-time, using messaging systems like Apache Kafka and frameworks like Apache Flink. It allows for immediate filtering, cleansing, analysis, and redistribution of data.
- Use Cases: Real-time fraud detection, monitoring of critical machinery in industries, and live dashboard updates are instances where streaming data pipelines are utilized.
Lambda Data Pipelines:
- Description: Lambda Architecture combines the strengths of both batch and real-time processing. It has a batch layer for handling large data sets and historical analysis and a speed layer for real-time processing. This dual approach provides a robust solution for handling vast amounts of data with low latency.
- Use Cases: Situations requiring real-time responses based on large datasets, such as real-time analytics platforms that also need to perform historical data analysis.
ETL (Extract, Transform, Load) Data Pipelines:
- Description: This involves acquiring data from various sources, transforming it for analysis, and loading it into a data warehouse. Challenges in ETL architecture include data integrity and latency.
- Use Cases: Predominantly used in scenarios where data from various sources needs standardization before it's analyzed in a data warehouse.
ELT (Extract, Load, Transform) Data Pipelines:
- Description: Data is first extracted, then loaded directly into the data system, and transformations are performed afterward. This is becoming more prevalent with the rise of powerful cloud data warehouses.
- Use Cases: Favorable in scenarios where the data warehouse can process transformations efficiently, making it more advantageous to transform after loading.
Data Pipeline vs. ETL & ELT: Understanding the Distinctions
Data pipelines, often linked with traditional ETL and its newer counterpart ELT, serve as comprehensive tools in data processing. While ETL transforms data before loading and ELT post-loading, data pipelines extend beyond, enabling real-time streaming and targeting various endpoints like data lakes or SaaS platforms. Integral to modern analytics and business intelligence, they also support tools like CRMs, facilitate data flow into SaaS through reverse ETL, and enrich product experiences when interfaced with production databases.
Scope of Operation:
- ETL (Extract, Transform, Load): This is a specific type of data pipeline that describes a sequential three-step process. Data is extracted from source systems, transformed into the desired format, and finally loaded into a destination database or data warehouse.
- ELT (Extract, Load, Transform): A variant of ETL, ELT processes first extract and load data into databases. The transformation occurs afterward, directly within the database.
- Data Pipeline: An overarching term, a data pipeline refers to the procedures and activities associated with transporting data between systems or applications. It can encompass ETL, ELT, or even just simple data ingestion without any transformation.
Transformation Necessity:
- ETL: Transformation is core to ETL, happening before the data is loaded into its final destination.
- Data Pipeline: Here, transformation is not always mandatory. Depending on the situation, data may be transformed before or after loading, or might bypass transformation altogether.
Process Finality:
- ETL: ETL operations traditionally conclude with the loading of data into the target system. Post this step, the ETL task is deemed complete.
- Data Pipeline: The end isn't strictly about data loading. These pipelines might continuously stream data, possibly triggering further processes or integrations beyond the primary load.
Functional Context:
- ETL & ELT: These primarily revolve around data migration to data warehouses to support analytics, business intelligence, and business applications such as advanced CRMs.
- Data Pipeline: This is a broader concept. While it might support ETL and ELT processes, it also extends to real-time (streaming) data transfers instead of just batches. The destination isn't restricted to data warehouses; data lakes or SaaS solutions are also valid endpoints. Additionally, when data pipelines channel data to production databases, this can be integrated into product experiences. Integration, workflow automation vendors, and reverse ETL data pipelines also facilitate moving data into SaaS platforms for operational analytics.
In essence, while there's an overlap, the distinction between a data pipeline, ETL, and ELT is marked by their scope, necessity for transformation, endpoint objectives, and functional context. Being aware of these differences can guide businesses in making informed decisions on data movement and processing.
Benefits and Challenges of Data Pipelines
Benefits:
- Consistency & Accuracy: By automating data processing, businesses achieve consistency, eliminating the discrepancies manual processes might introduce.
- Scalability: As businesses grow, so does their data. Modern data pipelines are built to scale, accommodating ever-increasing data volumes.
- Decision Empowerment: Quick, refined data means businesses can make informed decisions rapidly.
Challenges:
- Complexity: As data sources diversify, managing and integrating these sources become complex and costly.
- Maintenance: Pipelines aren’t set-and-forget. Regular maintenance is required to accommodate evolving data structures and business needs.
- Security: With data breaches becoming common, ensuring data security while it's in transit is paramount.
Evolution of Data Pipeline Architectures
Traditional Data Pipeline Architectures:
- Context: Marked the mainstream adoption of big data processing capabilities.
- Architecture: Data was primarily hosted in on-premises, non-scalable databases. The compute resources were often limited.
- Data Engineering Focus: Involved considerable time in modeling data and optimizing queries within constraints. Data pipeline architecture typically consisted of hardcoded pipelines using the ETL pattern for data cleaning, normalization, and transformation.
Modern Data Stack Era:
- Advancements: Emergence of cloud computing and modern data repositories like data warehouses, data lakes, and lakehouses.
- Shift in Architecture: Moved towards decoupling storage from compute, optimizing data pipeline architecture for speed and agility.
- ELT Pattern: Enabled more widespread analytics, experimentation, and machine learning applications due to the flexibility and scalability offered by cloud infrastructure.
Streaming Data Pipeline Architectures:
- Requirement: Growing need for near-real-time data, particularly for data science and machine learning.
- Architecture Pattern: Stream, collect, process, store, and analyze.
- Benefits: Offers valuable insights with near-real-time data processing.
- Challenges: Denormalization and preaggregation in these streaming data pipelines can delay data freshness for real-time analytics and limit flexibility, making it challenging to adapt to changing business needs. Adding more components to the system increases complexity and costs, heightening the risk of errors and potential system failures, which in turn can slow down the process of obtaining actionable insights.
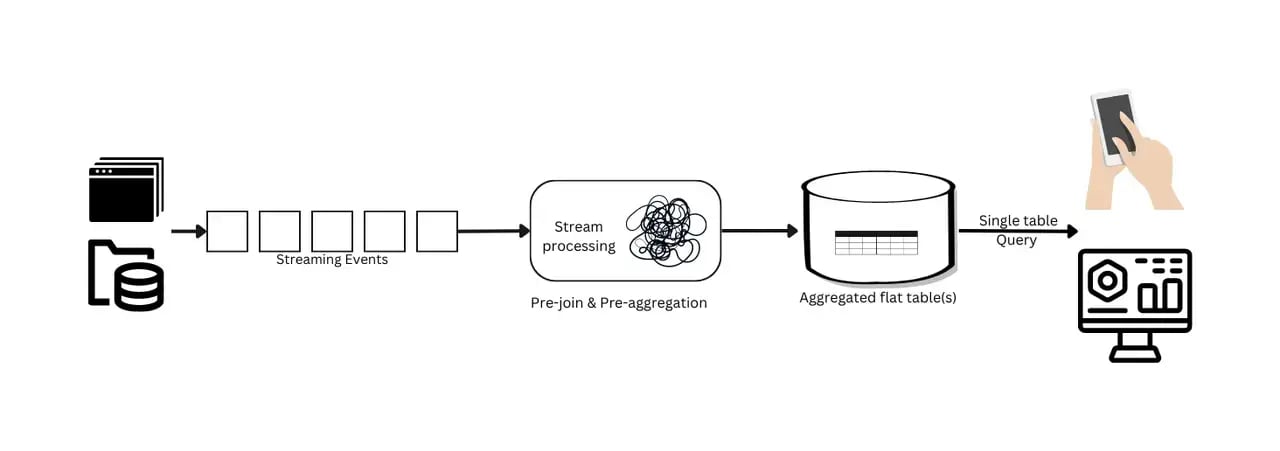
Emerging Architectures - Pipeline-Free for Real-Time Analytics:
- Definition: The concept of a "pipeline-free" approach in real-time analytics represents a significant shift from traditional data processing methods.Traditional real-time analytics often rely on preprocessing stages like denormalization and pre-aggregation, which can be expensive and inflexible. The "pipeline-free" approach eliminates these preprocessing stages, allowing direct querying of data without the need for time-consuming transformations.
- Challenges with Traditional Preprocessing Pipelines: The resource-intensive nature of JOIN operations in traditional real-time OLAP databases and the reliance on denormalization can lead to reduced flexibility, increased system complexity, and higher costs.
- Advantages of Going Pipeline-Free: his innovative approach aims to simplify real-time analytics and overcome the limitations of traditional methods, offering potential game-changing strategies for real-time analytics challenges
- How to achieve “pipeline-free” real-time analytics:
- Leverage On-the-fly JOIN Operations: Utilize advanced database technologies that allow for efficient on-the-fly JOINs, eliminating the need for denormalization in the data pipeline.
- Implement Internal Preaggregation: Use systems like StarRocks that manage preaggregation within the database itself, thereby streamlining the data preparation process.
Conclusion
Data pipelines are integral in the data-driven business world, playing a crucial role in data management and analysis. Understanding their types, benefits, challenges, and applications is essential for leveraging their potential. Simplifying and efficiently managing these pipelines can lead to more effective data utilization, driving informed business decisions.

.jpg)
