


Join StarRocks Community on Slack
Connect on SlackWhat is Single Instruction, Multiple Data (SIMD)?
SIMD, or Single Instruction, Multiple Data, refers to a class of computer architecture that allows a single CPU instruction to operate on multiple data elements simultaneously. Instead of executing the same operation repeatedly—once per element—SIMD performs that operation across an entire array (or vector) of data in a single step.
To understand this contrast, consider a scalar operation: if you're adding two arrays of numbers element by element, a scalar CPU would loop through them, adding one pair at a time. SIMD, by contrast, groups multiple elements into a vector register and adds them all at once using a single instruction. This approach dramatically reduces the instruction count and loop overhead, and makes better use of modern CPU pipelines.
SIMD is foundational to vectorized processing and is now standard in modern processor designs. Its hardware support has grown substantially since the 1990s. Early implementations like Intel’s Streaming SIMD Extensions (SSE) introduced 128-bit vector instructions; later generations, such as Advanced Vector Extensions (AVX) and AVX2, expanded this to 256 bits and beyond. These instruction set extensions enabled efficient parallel processing of integers and floating-point values across arrays, and became integral to domains like multimedia, scientific computing, and increasingly, database engines like StarRocks.
At its core, SIMD is about data parallelism: applying the same computation across many values in parallel. The more predictable and homogeneous the workload (e.g., a column of integers being filtered or summed), the better SIMD performs. That’s why it plays a central role in high-performance analytics, particularly within vectorized execution engines that process data in a columnar format.
How SIMD Works
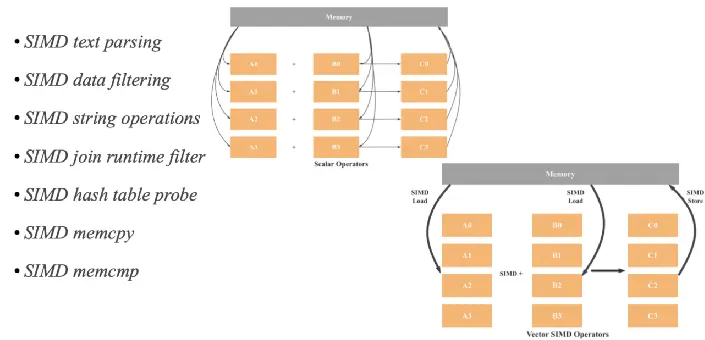
At a high level, SIMD improves performance by enabling a single CPU instruction to operate on multiple data elements in parallel. Rather than executing a loop where each instruction processes a single value (as in scalar execution), SIMD processes a vector of values in one instruction cycle.
Let’s break down the core mechanics of how this works:
1. Parallel Execution Model
Traditional CPUs follow a sequential model where instructions operate on one data item at a time. For example, summing 1,000 integers would require 1,000 iterations of a scalar addition instruction.
With SIMD, those same integers can be grouped into fixed-size vectors—say, 256 bits wide—and processed 8 at a time using a single instruction. This massively reduces loop overhead and increases instruction throughput.
2. Data Layout and Alignment
To take advantage of SIMD, data must be organized contiguously in memory—typically in arrays or columnar vectors—so the processor can load them efficiently into SIMD registers. Proper memory alignment is also critical: misaligned data can result in performance penalties or even runtime exceptions on some architectures. Vectorized execution engines (like in StarRocks) are designed to operate on these well-aligned, batch-structured data formats.
3. Specialized Instruction Sets
SIMD capabilities are exposed through architecture-specific instruction set extensions. Examples include Intel’s AVX2 (used by StarRocks), AVX-512, and ARM’s NEON. These instructions are baked into the processor’s microcode and are optimized for applying the same arithmetic or logical operation across all lanes in a vector register.
For example, an AVX2 instruction like _mm256_add_epi32 performs 8 simultaneous additions of 32-bit integers stored in a 256-bit register.
4. Vectorized Operations
Typical operations that benefit from SIMD include:
-
Arithmetic: addition, subtraction, multiplication
-
Logical comparisons: equality, greater-than, masking
-
Bitwise operations: shifts, AND/OR/XOR
-
Aggregations: summing or counting over batches
-
Filters: evaluating WHERE conditions across columns
In analytical systems, these operations are foundational. They underpin everything from basic filtering (WHERE value > threshold) to complex joins and aggregations.
5. Minimized Memory Traffic
One of the most important performance benefits of SIMD is reduced memory access. Since each instruction processes multiple data elements, fewer loads and stores are required overall. This alleviates memory bandwidth pressure and makes better use of CPU cache lines, which are typically 64 bytes wide and naturally align with SIMD vector sizes.
This optimization is especially critical for OLAP-style workloads, where performance often hinges more on memory I/O efficiency than raw compute.
6. Efficient Hardware Utilization
Modern CPUs are built with wide SIMD units that would otherwise sit idle if code isn’t vectorized. By issuing SIMD instructions, software makes full use of the processor’s execution pipelines, reducing idle cycles and improving energy efficiency. In practice, this means more rows processed per core, per clock cycle.
How SIMD Facilitates Vectorization

SIMD alone doesn’t guarantee performance gains. To fully benefit from its parallel execution model, your code—and your data—must be structured in a way that aligns with SIMD’s requirements. This process is called vectorization: transforming scalar logic into a form that can operate over vectors of data using SIMD instructions.
Vectorization is both a compiler optimization strategy and a manual engineering discipline. Below are the core steps that enable effective SIMD-backed vectorization, particularly in systems like StarRocks where performance at scale is critical.
Step 1: Code Vectorization
The first step is to rewrite or compile code so that operations over individual data items are grouped into batch operations over vectors. This can happen in two ways:
-
Automatic vectorization: Modern compilers (like GCC, Clang, or MSVC) can detect loop patterns and convert scalar operations into SIMD instructions. This requires writing code that follows predictable access patterns and avoids data dependencies that block parallelism.
-
Manual vectorization: For performance-critical code paths—such as expression evaluation in a query engine—it’s often necessary to use SIMD intrinsics or low-level libraries to write explicitly vectorized logic. StarRocks, for example, uses C++ intrinsics for AVX2 to accelerate filters, joins, and aggregations over columnar batches.
In both cases, the goal is to replace repetitive scalar instructions with fewer, wider vector instructions.
Step 2: Memory Alignment
SIMD instructions are sensitive to memory layout. Most SIMD registers expect data to be aligned to specific byte boundaries (e.g., 16-byte alignment for SSE, 32-byte for AVX2). If data is misaligned, the CPU may have to fall back to slower unaligned access, or worse, trigger segmentation faults.
To ensure high-throughput SIMD execution:
-
Data should be stored in contiguous arrays (not scattered across structs or heap allocations).
-
Allocators like
posix_memalign()or platform-specific directives can enforce proper alignment. -
Columnar storage formats—as used in StarRocks—naturally align with SIMD requirements, which is one reason vectorized databases benefit so much from these techniques.
Step 3: Loop Unrolling
Loop unrolling is a classic compiler optimization that increases the number of operations performed per iteration by duplicating loop bodies. This reduces the overhead of loop control (incrementing counters, evaluating conditions) and enables deeper instruction-level parallelism.
In SIMD pipelines, unrolling allows more instructions to be packed into each CPU cycle, minimizing stalls and improving utilization. It also increases the opportunities for the compiler to apply auto-vectorization.
Data access patterns have a direct impact on SIMD efficiency. If memory access is irregular (e.g., strided, pointer-chased, or nested), the processor will incur cache misses and misaligned loads.
Reordering the layout of data in memory—so that related fields are stored together in linear arrays—improves cache locality and vector loading efficiency. This is often referred to as “Structure of Arrays” (SoA) vs. “Array of Structures” (AoS) transformation.
In StarRocks and other columnar engines, this is baked into the storage model: each column is stored independently as a dense, type-consistent array, making it naturally vectorizable.
Step 5: Algorithmic Simplification
Even with aligned data and vector-friendly loops, performance bottlenecks can remain if the algorithm itself isn’t designed with parallelism in mind.
Key strategies include:
-
Avoiding data dependencies: For example, rewriting a cumulative sum (which is inherently sequential) as a tree-based prefix sum to allow partial vector computation.
-
Eliminating unnecessary branches: Conditional logic within SIMD lanes introduces complexity. Using mask-based operations and predicated execution avoids divergent control flow.
-
Reducing memory footprint: By operating in-place or avoiding materialization of intermediate results, vectorized code stays within cache longer.
These algorithm-level optimizations are often what separate a "technically vectorized" implementation from a truly high-performance one.
In short, SIMD facilitates vectorization, but the real gains come when code, memory layout, loop structure, and algorithms are all tuned to work in concert. This full-stack optimization approach is what enables systems like StarRocks to push past the traditional performance ceilings of scalar query engines—especially for real-time, high-concurrency workloads across large, columnar datasets.
Benefits and Trade-offs of SIMD in Vectorized Query Engines
Increased Throughput and Instruction Efficiency
SIMD dramatically improves throughput by executing a single instruction across multiple data elements in parallel. This reduces instruction count and loop overhead, allowing systems like StarRocks to process significantly more rows per CPU cycle. In large-scale OLAP scenarios, this means filters, joins, and aggregations execute faster and with greater consistency under load.
Example: A filter like WHERE amount > 100 applied to millions of rows can be evaluated eight values at a time using AVX2, accelerating scan time and reducing total CPU usage. StarRocks employs this technique to support sub-second latency in customer-facing dashboards, including workloads from Pinterest and Eightfold.ai.
Optimized Cache and Memory Utilization
Because SIMD operates on contiguous memory blocks, it aligns naturally with CPU cache lines. This improves spatial locality, reduces cache misses, and minimizes memory stalls. Columnar storage formats further reinforce this advantage by storing data in tightly packed arrays.
Example: When aggregating float columns, StarRocks loads batches of values directly into cache-aligned SIMD registers, reducing memory fetch frequency and speeding up reductions like SUM(duration).
Improved CPU Utilization and Energy Efficiency
Modern CPUs contain wide vector execution units. Without SIMD, these units sit underused. By feeding them with vectorized instructions, StarRocks ensures that every clock cycle processes multiple data points. This not only improves performance but also reduces power consumption per operation.
Developer Accessibility Through High-Level Tooling
Although SIMD operates at the hardware level, developers do not need to write low-level assembly. Compilers can vectorize loops automatically under the right conditions, and libraries like Intel Intrinsics expose vector types in C++. StarRocks uses these intrinsics in performance-critical parts of the engine.
Challenges in SIMD Implementation
Vectorization Complexity
Not all code is vectorizable. Loops with data dependencies, branches, or pointer indirection often block auto-vectorization. Manual restructuring is required to unlock SIMD benefits.
Data Dependencies Across Vector Lanes
SIMD assumes each data element is processed independently. Algorithms that involve sequential dependencies—like cumulative sums—must be restructured to enable parallelism. This adds implementation complexity and often requires hybrid scalar-vector solutions.
Memory Alignment Constraints
SIMD instructions often require memory to be aligned to 16- or 32-byte boundaries. Misaligned data access leads to performance degradation or crashes. StarRocks mitigates this by using aligned memory allocation and columnar data formats that naturally conform to alignment rules.
Architectural Portability
SIMD instruction sets differ by CPU family. AVX2, AVX-512, NEON, and RISC-V vectors are incompatible. Porting code across platforms requires abstraction layers, runtime dispatch, or fallback logic, increasing maintenance effort in cross-platform engines.
Load Imbalance and Masking Overhead
When conditional filters leave only a few active values in a vector, the remaining SIMD lanes go unused. This results in lower efficiency, particularly in highly selective queries. Engines like StarRocks address this by dynamically adjusting batch sizes and applying efficient masking logic.
In Summary
SIMD introduces a new layer of parallelism within each CPU core, but unlocking its full potential demands:
-
Careful vectorization strategy
-
Memory alignment guarantees
-
Architecture-aware implementation
-
Algorithm redesign in some cases
In practice, high-performance systems like StarRocks address these challenges through columnar layout, explicit intrinsics, alignment-aware memory allocators, and selective algorithm tuning—enabling SIMD to deliver real-world speedups without compromising reliability or maintainability.
SIMD Optimization in StarRocks
StarRocks is built from the ground up in C++ to fully exploit SIMD (Single Instruction, Multiple Data) across its entire query execution engine. This isn't a superficial enhancement—it’s a foundational design choice that enables the system to push performance well beyond traditional row-based or partially vectorized engines.
Vectorized Execution Meets SIMD
At the heart of StarRocks is a fully vectorized execution model, where all operators—from scan and filter to joins and aggregations—operate on columnar batches of data. Each batch is represented as a vector in memory, and SIMD instructions are used to apply the same operation to every element in that vector simultaneously.
This architecture allows StarRocks to process many data points per CPU cycle, significantly reducing instruction count and memory fetch frequency. For example, an AVX2 instruction can perform arithmetic on 8 integers or 4 doubles at once, making it ideal for OLAP workloads where the same operation must be repeated over large datasets.
SIMD in Practice: Operators That Benefit
SIMD optimization is applied broadly across StarRocks' execution pipeline:
-
Filters: Conditions like
WHERE value > thresholdare evaluated in batches, using SIMD to compare multiple values in parallel. -
Joins: SIMD accelerates hash probe operations by evaluating multiple join keys simultaneously, improving throughput in multi-way or high-cardinality joins.
-
Aggregations: Vectorized accumulators leverage SIMD to sum, count, or average column values with minimal instruction overhead.
-
Text Parsing: Even string-heavy operations like JSON tokenization or substring matching benefit from SIMD-accelerated pattern matching and buffer scanning.
This broad SIMD coverage helps StarRocks maintain consistent low-latency execution even as concurrency and dataset size increase.
Real-World Impact
Several production deployments validate the performance gains enabled by StarRocks’ SIMD-accelerated engine:
-
Pinterest replaced their Apache Druid clusters with StarRocks and saw 50% lower latency and 3× better cost-performance on high-concurrency partner insights dashboards. SIMD acceleration played a key role in enabling low-latency execution for filters, joins, and aggregations under real-world production load.
-
TRM Labs, operating a petabyte-scale blockchain analytics platform, chose StarRocks for its ability to handle complex aggregation queries on Iceberg tables with sub-second response times, even under high concurrency. SIMD-based vectorized execution allowed them to meet strict SLA targets while keeping infrastructure costs manageable.
-
Eightfold.ai migrated from Amazon Redshift to StarRocks to overcome concurrency and leader-node bottlenecks. SIMD acceleration enabled StarRocks to sustain interactive analytics across multi-tenant customer datasets, including event-level join operations and behavioral scoring across large fact tables.
-
Herdwatch, serving real-time dashboards for agri-tech analytics, reported reducing query latency from 2–5 minutes (Athena) to 700 ms–1.5 seconds after migrating to StarRocks + Iceberg. SIMD-powered vectorized scans and filters on structured sensor and livestock data played a crucial role in enabling this performance jump.
Hardware Requirement: AVX2
To support its vectorized engine, StarRocks requires the AVX2 instruction set to be present on all compute nodes. AVX2 provides 256-bit SIMD vector registers and instruction support, which are essential for achieving the system’s high throughput per core. This requirement ensures that the engine can reliably execute vectorized operations at hardware speed across all workloads.
In summary, SIMD is not just an optimization layer in StarRocks—it is a core design principle. By integrating SIMD across every stage of query execution and combining it with a tightly aligned columnar storage format, StarRocks delivers the kind of performance required for modern, high-concurrency, and real-time analytics. From filters to joins to string parsing, SIMD enables StarRocks to push more data through the CPU per clock cycle than traditional engines ever could.
Conclusion
SIMD—Single Instruction, Multiple Data—is a cornerstone of modern computational performance. At its core, SIMD embodies the idea of doing more with less: one instruction, multiple data points, executed in parallel. From image processing and physics simulations to real-time analytics in vectorized databases like StarRocks, SIMD unlocks a new level of throughput and hardware efficiency.
But SIMD is more than just fast math. It’s a philosophy of data layout, memory alignment, loop structure, and compiler optimization. Effective SIMD isn’t just about having the right instruction set (like AVX2 or SSE); it’s about designing your system to exploit parallelism at every level—from the processor core to how data is fed into the pipeline.
For anyone building high-performance systems—whether you’re optimizing inner loops in C++, running large-scale analytics queries, or building infrastructure like StarRocks—understanding and using SIMD isn’t optional. It’s essential. It’s what turns a good system into a great one.
Frequently Asked Questions (FAQ)
Q1. What’s the difference between SIMD and multithreading?
SIMD runs one instruction on multiple data points at once, using CPU vector registers. Multithreading runs multiple instructions (or tasks) concurrently across multiple CPU cores. They are orthogonal: SIMD accelerates each thread, while multithreading runs many threads in parallel.
Q2. What types of operations benefit most from SIMD?
SIMD shines in data-parallel tasks where the same operation is applied repeatedly—like:
-
Array math (e.g., addition, multiplication)
-
Image filtering
-
Signal processing (FFT, convolution)
-
Text search and regex parsing
-
Vectorized database queries (filters, joins, aggregations)
Q3. What instruction sets enable SIMD on modern CPUs?
-
SSE: Streaming SIMD Extensions (Intel, legacy 128-bit)
-
AVX / AVX2 / AVX-512: Advanced Vector Extensions, 256–512-bit
-
NEON: ARM-based SIMD (e.g., for mobile)
-
RISC-V V-Extension: Upcoming vector instructions in open-source ISA
StarRocks, for example, requires AVX2 to enable its vectorized execution engine.
Q4. What are the prerequisites for writing SIMD-enabled code?
-
A CPU with SIMD instruction support (like AVX2)
-
Compiler support (GCC, Clang, MSVC with
-mavx2flags) -
Proper data alignment in memory (often 16 or 32-byte alignment)
-
Libraries or intrinsics (e.g.,
__m256for AVX in C/C++)
Optional: Loop unrolling, algorithm tuning, and data layout optimization for best results.
Q5. Can SIMD be used in high-level languages like Python?
Yes—indirectly. While Python itself doesn’t expose SIMD instructions natively, libraries like:
-
NumPy (compiled with SIMD-enabled BLAS/LAPACK)
-
Numba (JIT compiler that auto-vectorizes)
-
PyTorch and TensorFlow (leverage SIMD under the hood)
can use SIMD via compiled backends. Developers benefit from SIMD even when not writing low-level code.
Q6. How does SIMD improve database performance in StarRocks?
SIMD unlocks substantial performance gains in StarRocks by enabling its fully vectorized, columnar execution engine to process multiple data elements in a single CPU operation. Rather than handling one row at a time, StarRocks batches operations into vectors—often sized to fit a single SIMD register (e.g., AVX2’s 256-bit width).
Here’s how it accelerates key database operations:
-
Filtering & Scanning
AWHERE age > 30clause can evaluate eight 32-bit integers in one vector, reducing loop overhead and memory fetches—yielding faster scans. -
Joins & Hash Comparisons
Hash-based joins compare many keys per instruction. SIMD performs multiple comparisons in parallel, speeding up join probes across partitions. -
Aggregations
Operations likeSUM,AVG, orCOUNToperate on float or integer batches at once. Vectorized aggregation cuts instruction count dramatically compared to scalar accumulation. -
String Parsing & Text Operations
Even text-heavy workloads benefit. StarRocks uses SIMD-based parsers (e.g., vectorized JSON tokenizer) to accelerate regex, string manipulations, and serialization tasks across many characters.
Why It Matters
-
Higher Throughput & Core Utilization: SIMD lets each CPU core handle dozens of rows per cycle, rather than one.
-
Better Cache Performance: Columnar, batched data fits cache lines more effectively, reducing memory stalls.
-
Major Speedups: StarRocks often reports 3–10× improvements in operator performance thanks to SIMD optimizations.
In short, SIMD is fundamental to StarRocks’ ability to sustain high concurrency, low-latency, and real-time analytics—by transforming core operations into vector-parallel routines matched to modern CPU architectures.
Q7. What Are the Biggest Challenges in SIMD Optimization?
-
Data Alignment
SIMD instructions often require data to be aligned to specific byte boundaries (e.g., 16-byte for SSE, 32-byte for AVX) to avoid performance penalties or even crashes. Misaligned loads can cause slower unaligned access or trigger hardware faults.
Solution: Use aligned memory allocators (posix_memalign) or language directives (__attribute__((aligned))), and follow Intel’s alignment recommendations. -
Data Dependencies
SIMD excels when operations on each element are independent. If one lane depends on another’s result—such as cumulative sums or chained operations—parallelism breaks, leading to reduced performance or complexity in handling dependencies .
Solution: Rewrite algorithms to eliminate dependencies (e.g., use prefix-sums via tree-based methods) or apply partial processing when required. -
Branching and Control Flow
Diverging branches (e.g.,if (x[i] > 0)) within SIMD lanes force some to idle or rely on masking, which incurs overhead and complexity.
Solution: Prefer branch-free expressions using predication (e.g.,mask = x > 0; y = mask * a + (1-mask) * b;), or restructure loops to minimize divergent logic. -
Portability Across Architectures
SIMD instruction sets vary across platforms: SSE, AVX, NEON, RISC-V V, etc. Writing optimized code on one platform may not run on another hardware.
Solution: Use abstraction layers or conditional compilation to target multiple ISA sets. Offer fallback scalar implementations and perform runtime ISA detection for best performance. -
Debuggability and Maintainability
SIMD code often uses low-level intrinsics or assembly, making it hard to read, test, and debug. Breakpoints and scalar-oriented debuggers may not reflect lane-level behavior.
Solution: Encapsulate SIMD logic in well-documented helper functions, enable verbose logging or validation layers, and use SIMD-aware debugging tools (e.g., Intel VTune, AMD’s CodeXL).
By proactively addressing these challenges—alignment, dependencies, branching, portability, and toolchain maturity—you can harness SIMD for major performance gains without compromising reliability or maintainability.
.jpg)

