


Questions About Vectorization?
Connect on SlackWhat is Vectorization?
Let’s start with the core idea. When we talk about vectorization in databases, we’re referring to a set of techniques that allow modern CPUs to process multiple data points in parallel using a single instruction. This is done via SIMD—Single Instruction, Multiple Data.
It’s the opposite of the old model—SISD (Single Instruction, Single Data)—where a loop would touch one value at a time. In SIMD, one instruction might touch eight, sixteen, or even thirty-two values in one go, depending on the CPU’s vector width.
The Impact of Vectorization on Database Performance
When we talk about vectorization accelerating database performance, we’re really talking about making better use of the CPU. To understand how that happens, we first need to look at how CPU time is consumed and what levers are available to optimize it.
Understanding CPU Performance in the Context of Vectorization
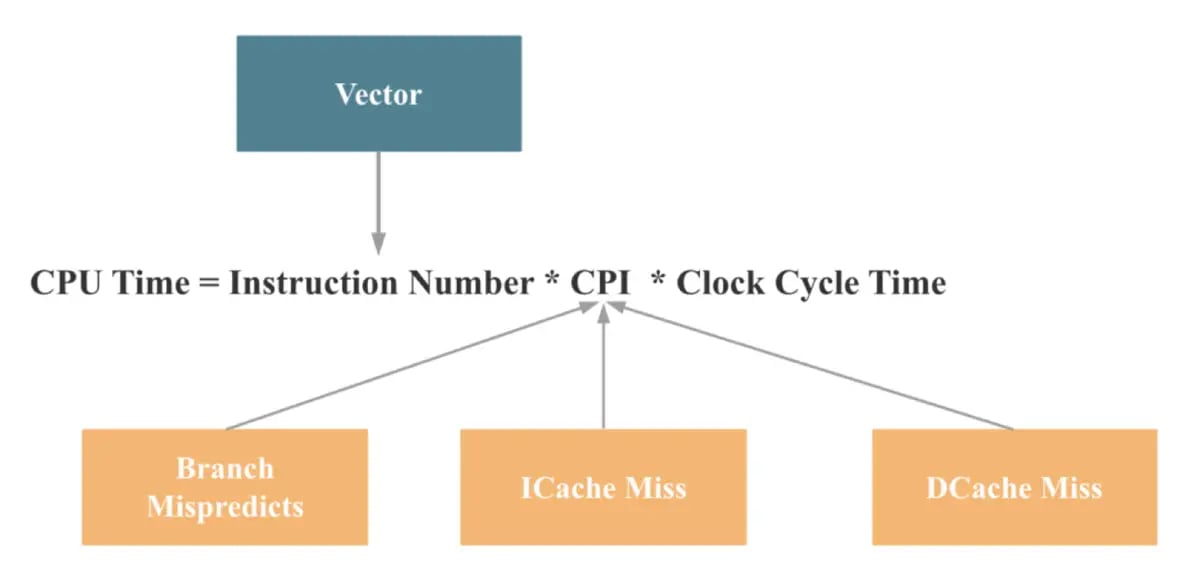
A useful starting point is the classic formula for CPU execution time:
CPU Time = Instruction Count × CPI × Clock Cycle Time
Let’s break this down:
-
Instruction Count is the total number of instructions executed.
-
CPI (Cycles Per Instruction) reflects how many CPU cycles each instruction takes.
-
Clock Cycle Time is the time taken per clock cycle—determined by hardware.
Since we typically don’t control the clock speed (that’s hardware territory), we focus on reducing either the number of instructions or the cycles per instruction. And that’s where vectorization shines—it reduces instruction count by processing multiple values with a single instruction and improves CPI by keeping the CPU’s execution units better utilized.
Thinking Like the CPU: A Quick Recap
Modern CPUs are built for parallelism. But they won’t go fast on their own—you have to feed them right.
Each core has special vector registers that allow a single instruction to act on multiple data points. Think of these registers like wide lanes on a highway: the more lanes you fill, the more cars (data) you can move per second.
Here's how SIMD vector widths have evolved:
-
SSE (Streaming SIMD Extensions): 128-bit — 4 x 32-bit integers per instruction
-
AVX2: 256-bit — 8 x 32-bit integers
-
AVX-512: 512-bit — 16 x 32-bit integers
Now picture this: you're summing a billion numbers in a query.
-
In scalar execution (SISD), each number is processed individually—so that's a billion additions.
-
In vectorized execution (SIMD), you might process 8 or 16 numbers in one shot—slashing the instruction count by 8x to 16x.
Even if real-world gains are tempered by memory latency or branching, the performance uplift is still massive. This kind of optimization is especially crucial in analytical databases where the bottleneck isn't disk or network, but raw CPU throughput.
Where Vectorization Comes Into Play in Databases
Let’s break down the common stages of a query pipeline in OLAP systems and see where vectorization adds value:
| Stage | Operation | How Vectorization Helps |
|---|---|---|
| Scan | Reading column values | SIMD-based decoding, null filtering |
| Filter | WHERE clause | Apply predicates across batches using vectorized masks |
| Projection | SELECT expressions | Apply arithmetic, logical ops in bulk |
| Aggregation | SUM, AVG, COUNT | Use accumulators over column vectors |
| Join | Hash join, nested loop | Vectorized probe & comparison routines |
| Sort | Top-K, ORDER BY | SIMD comparisons, key swapping |
Let’s look at some of these in detail.
Filtering with SIMD
Take a WHERE clause like:WHERE age > 30 AND income < 100000
In a scalar model, each row is checked one at a time. In a vectorized model, the engine loads a batch of 1,024 age and income values, applies the predicate across the batch using vector masks, and filters in one go. The result is a bitmap or selection vector, which is then used downstream to process only the qualifying rows.
Real-world example: In StarRocks, filtering is deeply vectorized and operates on column batches of up to 4,096 rows. This helps reduce CPU cycles per row to as low as 1–2 instructions, even for complex conditions.
Expression Evaluation
SQL expressions—like price * quantity - discount—can be compiled into vectorized operators that work on entire column vectors instead of looping over rows.
This is especially useful for:
-
Mathematical ops
-
Date/time extraction
-
Null checking
It also reduces branching (e.g., if-else), which is toxic for CPU pipelines.
Aggregation
Aggregation is where vectorization really shines. Think of a SUM(sales) over 1 billion rows. With vectorization:
-
Load a vector of
salesvalues -
Use vector accumulators to sum in batches
-
Reduce final result
SIMD accumulation uses fewer instructions and is more cache-friendly.
Production example: At Demandbase, StarRocks handles rollups on billions of event rows (think: page views, ad clicks, impressions) in near real time thanks to a fully vectorized aggregation engine. These queries used to run in seconds; now they run in hundreds of milliseconds—even at high concurrency.
Joins
Vectorization in joins is more nuanced. You don’t always get a 10x speedup, but you do get significant wins in:
-
Hash probe performance: Compare 8 keys at once
-
Predicate pushdown during probe
-
Batch processing in hash table lookups
This matters most for star schemas where a large fact table joins to smaller dimension tables.
StarRocks example: In a retail analytics use case, StarRocks can join a billion-row order table to a million-row product table using hash joins with vectorized probe—at speeds that previously required denormalized materializations.
Vectorized Execution Engine: Architectural Requirements
Now let’s talk about what a database needs to actually make vectorization work.
1. Columnar Data Layout
SIMD thrives when data is contiguous in memory. That’s why vectorized engines operate on columnar batches—not rows.
Implication: Your storage engine, buffer pool, and intermediate data structures all need to be column-oriented.
2. Batch-Oriented Execution
Instead of processing row-by-row, vectorized engines operate on fixed-size batches (typically 1k–4k rows). This makes CPU prediction more accurate and helps with cache locality.
3. Vectorized Operators
Operators like Filter, Join, Aggregate, and Sort need to be rewritten from scalar logic into vectorized logic. That’s not trivial—it’s a full rewrite.
Case Study: StarRocks
StarRocks is a prime example of a vectorized OLAP engine, built ground-up for performance. Here’s what makes it tick:
StarRocks is a fully vectorized MPP OLAP engine, designed from the ground up with columnar execution and SIMD acceleration at its core. Every major query operator in StarRocks—whether it’s filter, aggregation, join, or even text parsing—is vectorized and implemented in C++, making it highly cache-friendly and SIMD-optimized.
This means StarRocks doesn’t just use vectorization in simple math expressions. It processes all data in columnar batches and applies SIMD instructions broadly, across as many components as possible. For example, a WHERE clause, a GROUP BY operation, and even string parsing logic (e.g., extracting tokens from JSON) are SIMD-aware, enabling tight, predictable CPU loops that touch memory less frequently and execute more work per instruction.
Because of this architectural design, AVX2 support is a baseline requirement for StarRocks deployments. AVX2 (a 256-bit SIMD instruction set) is used to process wide batches of data with high throughput, helping StarRocks sustain high performance across large-scale analytical workloads.
The result: significantly faster query execution even under high concurrency, with better CPU efficiency and reduced latency—especially for large-batch operations typical in star schemas, dashboards, and real-time analytics use cases.
Practical Use Cases Where Vectorization Shines
1. User Behavior Analytics
Queries over billions of clickstream or event logs—like count of sessions by region and browser—run 5–10x faster with vectorized execution.
2. Real-Time Dashboards
High-concurrency analytics (e.g., customer metrics per minute) need low CPU overhead per query. Vectorization lowers per-query CPU cost, enabling 100s–1000s of concurrent queries.
3. SaaS Metrics Platform
For platforms offering per-tenant metrics (e.g., usage stats, billing, telemetry), vectorization enables tenant isolation without sacrificing performance.
Common Pitfalls in Vectorized Systems
Not all vectorized engines are created equal. Here are a few traps:
-
Poor memory alignment: SIMD loads/stores require aligned memory; misalignment kills performance.
-
Excessive branching: If-else logic or null checking that isn’t handled with masking can break SIMD.
-
Denormalized data: If the engine isn’t good at joins, you may denormalize—then lose the benefits of vectorized joins.
This is why systems like StarRocks invest deeply in SIMD-aware join processing and normalized schema support.
Beyond CPUs: The Next Frontier
While SIMD on CPUs has gotten us far, some workloads need more.
1. GPU-Based Vectorization
GPU databases (like OmniSci) use thousands of lightweight threads to do SIMD at massive scale. But transferring data between CPU and GPU is expensive and often not worth it unless queries are large and infrequent.
2. FPGAs and Vector Cores
In cloud-native scenarios, you may see FPGA-accelerated query fragments (e.g., regex filter on logs) or custom vector cores embedded in smart NICs.
But for most use cases today, well-optimized CPU SIMD gets you 80–90% of the performance gain without the operational complexity of GPU or FPGA.
Final Thoughts
Let’s wrap it up.
Vectorization isn’t just a compiler trick. It’s a philosophy of execution that permeates every layer of the query engine—from storage layout to runtime operators.
In a world where data sizes are exploding and real-time insights are expected, vectorization is not optional—it’s foundational.
If you’re evaluating a modern OLAP database, ask:
-
Does it do end-to-end columnar execution?
-
Are operators vectorized or scalar?
-
Does it support SIMD filter + join + aggregate?
-
How does it perform with normalized data?
Systems like StarRocks have shown that with vectorization, you can drop CPU usage by half, slash query latency, and still maintain real-time responsiveness.
And that’s why vectorization isn’t just a buzzword—it’s a key pillar of performance-first analytical systems.
FAQ: Vectorization in Databases
Q1: How is vectorization different from multithreading?
A: Vectorization (SIMD) and multithreading are complementary. Vectorization operates within a single CPU core, using wide registers to process multiple values per instruction. Multithreading operates across cores, assigning different tasks or data chunks to different threads. Think of SIMD as adding more seats per car, and multithreading as adding more cars to the road. Modern databases like StarRocks combine both: vectorized execution inside each thread, and multi-threaded execution across the cluster.
Q2: Do all databases support vectorized execution?
A: No. Only modern OLAP engines like StarRocks, DuckDB, ClickHouse, and Vectorwise offer full vectorized execution. Traditional row-oriented databases like MySQL or PostgreSQL may use some CPU instruction-level optimizations but generally lack batch-oriented, columnar vector processing. Even among columnar systems, vectorization quality varies: some engines only vectorize expressions, while others, like StarRocks, vectorize every operator, including joins and text parsing.
Q3: What kind of performance gains can I expect from vectorization?
A: That depends on the workload. For CPU-bound analytical queries—especially those involving filters, aggregations, or scans—5x–10x improvements in instruction throughput are common. At Demandbase, for instance, StarRocks reduced query latency from seconds to sub-second response times by applying end-to-end vectorization, even on large, normalized datasets. The biggest wins come when the CPU is the bottleneck and data is already in memory.
Q4: Does vectorization help with joins too? Aren’t they memory-bound?
A: It does help—particularly in the probe phase of hash joins and in predicate evaluation during joins. SIMD instructions can probe hash tables with multiple keys at once, apply multiple filters in parallel, and reduce branching during join logic. It won’t magically fix a bad join strategy or poor data modeling, but it significantly reduces per-row CPU overhead. That’s why StarRocks focuses on SIMD-aware join algorithms that maintain performance even with normalized data.
Q5: Is vectorization useful for OLTP databases too?
A: Not really. OLTP workloads are write-heavy and operate on small numbers of rows with high latency sensitivity. They don’t benefit much from batch processing or SIMD. Vectorization shines in OLAP—where queries touch millions or billions of rows. If you're designing a system to support high-throughput analytical queries (dashboards, cohort analysis, metrics aggregation), vectorization is a must-have.
Q6: How can I tell if my engine is using SIMD/vectorization?
A: There are a few ways:
-
Check the documentation: engines like StarRocks explicitly state SIMD and AVX2 as core requirements.
-
Use performance profiling tools (like
perf,vtune, orperf top) and look for SIMD instructions likevaddps,vmovdqa, etc. -
Monitor CPU utilization and query profile: SIMD tends to lower instruction count and increase cache hits.
-
Some engines expose vectorization status in EXPLAIN or query profile output.
Q7: Why is columnar storage important for vectorization?
A: SIMD instructions require contiguous memory access. Columnar formats store each column as a single continuous array, which aligns perfectly with vector loads/stores. Row-oriented formats scatter values from different columns across memory, making SIMD much less efficient. Columnar layout also improves CPU cache usage and reduces branching in filters or expressions.
Q8: Does vectorization require special hardware?
A: It requires a modern CPU that supports SIMD instruction sets like AVX2 or AVX-512. Most x86 servers built after 2013 (Intel Haswell and beyond) support AVX2. In fact, StarRocks explicitly requires AVX2-capable CPUs for production deployment. If you're running on ARM or other architectures, SIMD instructions exist but the instruction sets differ (e.g., NEON for ARM).
Q9: Can I write my own vectorized code in SQL or UDFs?
A: Not directly. Vectorization happens at the query engine layer, below the SQL abstraction. However, some systems allow UDFs to be written in vectorized form (e.g., DuckDB or ClickHouse with SIMD intrinsics). In StarRocks, native functions are SIMD-optimized, but UDFs written in Java or SQL typically won’t be vectorized unless implemented in native C++ and registered with the engine.
Q10: What’s the catch? Are there any downsides to vectorization?
A: Yes. Vectorized engines are complex to implement and require:
-
Aligned memory allocation
-
Branchless logic and masking to avoid breaking SIMD pipelines
-
Batch-oriented execution, which adds some latency for small queries
-
Minimum hardware requirements (e.g., AVX2)
Also, debugging and extending vectorized code paths (especially in C++) is more difficult than scalar code. But for large-scale analytics, the performance tradeoff is absolutely worth it.
.jpg)

